1. Introduction
1.1 Preface
本系列博文是和鲸社区的活动《20天吃掉那只PyTorch》学习的笔记,本篇为系列笔记的第三篇—— Pytorch 的层次结构。该专栏是 Github 上 2.8K 星的项目,在学习该书的过程中可以参考阅读《Python深度学习》一书的第一部分"深度学习基础"内容。
本系列博文是和鲸社区的活动《20天吃掉那只PyTorch》学习的笔记,本篇为系列笔记的第三篇—— Pytorch 的层次结构。该专栏是 Github 上 2.8K 星的项目,在学习该书的过程中可以参考阅读《Python深度学习》一书的第一部分"深度学习基础"内容。
本系列博文是和鲸社区的活动《20天吃掉那只PyTorch》学习的笔记,本篇为系列笔记的第二篇—— Pytorch 的核心概念。该专栏是 Github 上 2.8K 星的项目,在学习该书的过程中可以参考阅读《Python深度学习》一书的第一部分"深度学习基础"内容。
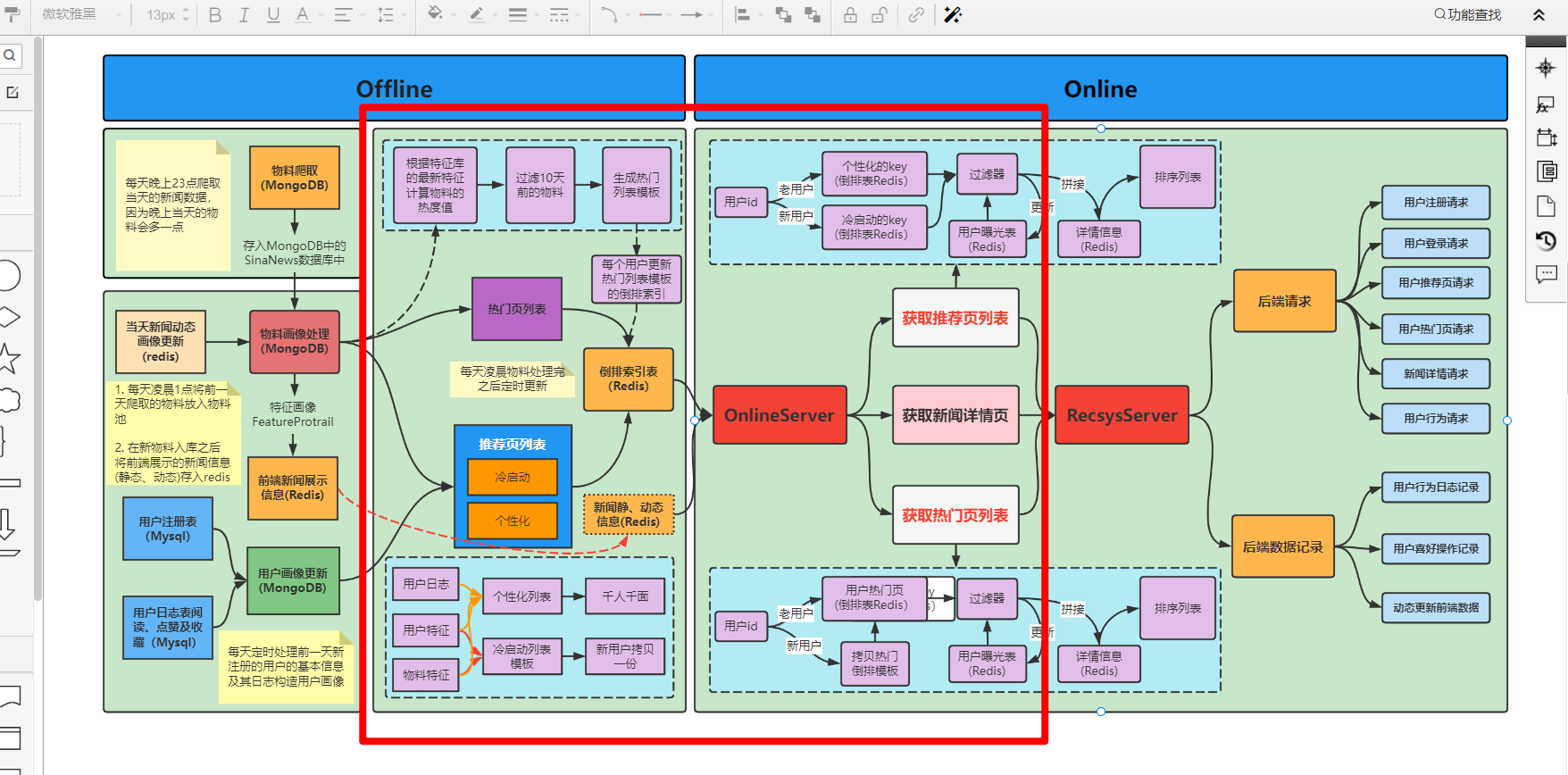
本篇文章主要是讲解推荐系统流程构建,主要包括Offline和Online两个部分。
offline部分主要是基于前面存储好的物料画像和用户画像进行离线计算, 为每个用户提供一个热门页列表和推荐页列表并进行缓存, 方便online服务的列表获取。 所以下面主要帮大家梳理这两个列表的生成以及缓存到redis的流程。
本文属于新闻推荐实战—前后端基础及交互—前后端交互部分。在前两节,我们分别简单的介绍了与本项目相关的前后的基础知识,目的是为了让大家更加细致的了解整个系统的前后端交互细节,以及更全面的了解一个推荐系统所需的组成部分。本文将从前后端的交互逻辑出发,更加全面的为大家讲解系统的每个细节,了解一个简单的推荐系统内的内部组成。
本文属于新闻推荐实战-数据层-构建物料池之 scrapy 爬虫框架基础。对于开源的推荐系统来说数据的不断获取是非常重要的,scrapy 是一个非常易用且强大的爬虫框架,有固定的文件结构、类和方法,在实际使用过程中我们只需要按照要求实现相应的类方法,就可以完成我们的爬虫任务。文中给出了新闻推荐系统中新闻爬取的实战代码,以便读者可以快速掌握 scrapy 的基本使用方法,并能够举一反三。
本文属于新闻推荐实战—数据层—构建物料池之 MySQL。MySQL 数据库在该项目中会用来存储结构化的数据(用户、新闻特征),作为算法工程师需要了解常用的 MySQL语法(比如增删改查,排序等),因为在实际的工作经常会用来统计相关数据或者抽取相关特征。本着这个目的,本文对 MySQL 常见的语法及 Python 操作 MySQL 进行了总结,方便大家快速了解。
本项目为企查查注册企业信息爬取,项目来源是别人的实验需求。故本博客会对项目的具体数据进行脱敏处理,其中涉及的 1168 个链接本文不进行提供,也不提供成品数据。