10. 大模型之 Adaptation
使用语言模型(例如在上下文学习中)通过仅给出提示,我们已经能够执行一些任务。然而,提示方法并不适用于全部的下游任务,如自然语言推理
NLI、问题回答
QA、将网络表格转换为文本、解析电子健康记录 EHR
等。
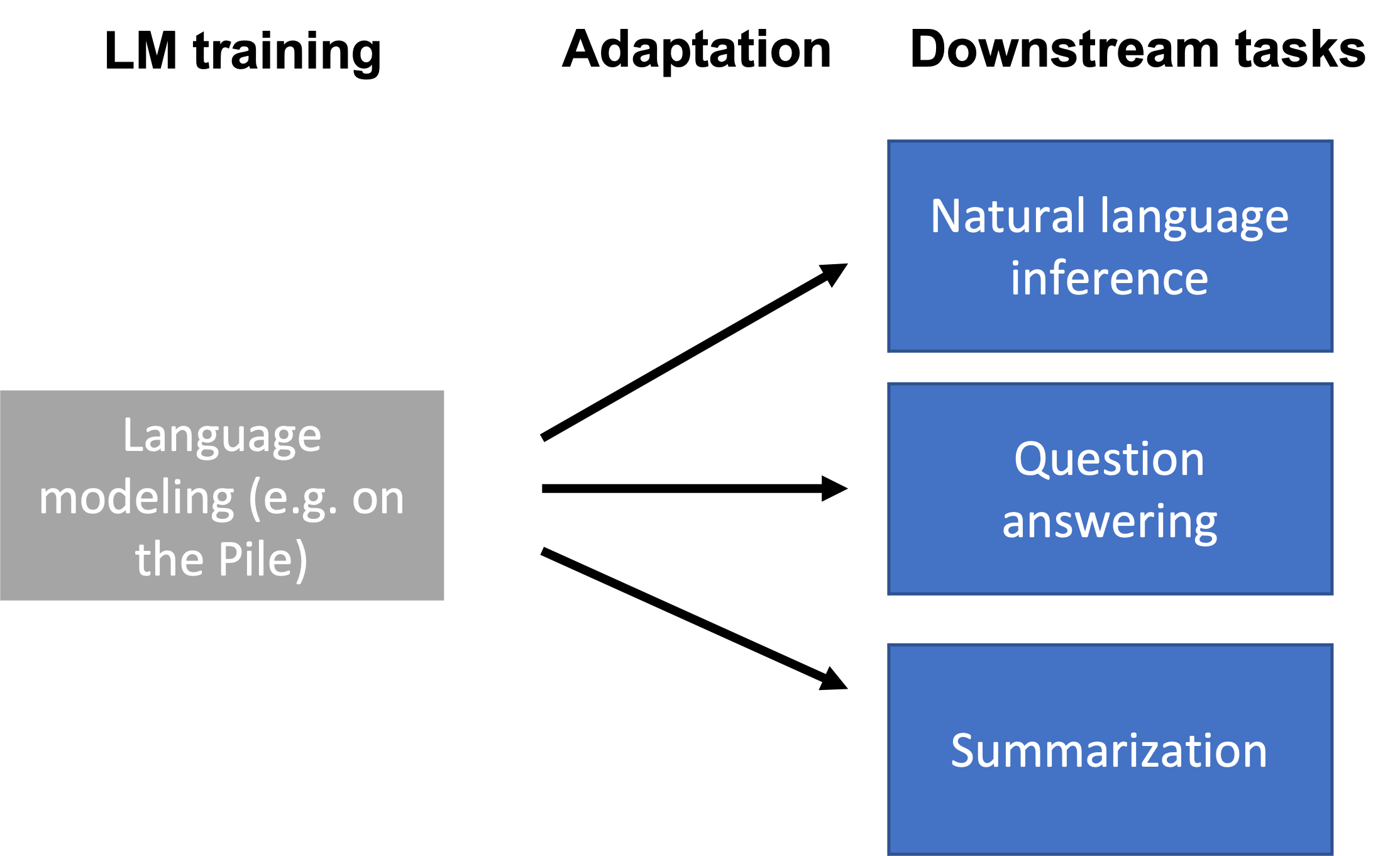
下游任务与语言模型的训练数据(例如,Pile
数据集)可能在格式和主题上有所不同,或者需要随时间更新新知识。因此,语言模型需要使用特定于任务的数据或领域知识来针对下游任务进行适配
10.1 为什么需要Adaptation
在探讨这一问题之前,我们需要理解语言模型如何被训练,并明确下游任务与原始训练任务之间可能存在的不同之处。
从语言模型的训练方式来说,语言模型,例如
GPT-3,通常是任务不可知(task-agnostic)的,这意味着它们在一个广泛的领域内进行训练,而不是针对特定任务。这种方法的优点在于模型具有广泛的适用性,但也带来了一些挑战。
由于下游任务的多样性,语言模型的预训练方式可以非常不同,这可能导致问题。例如,自然语言推理
NLI 任务与 Pile
数据集上的语言建模任务可能完全不同。
例子:
- Premise: I have never seen an apple that is not red.
- Hypothesis: I have never seen an apple.
- Correct output: Not entailment (the reverse direction would be entailment)
这种格式对模型来说可能并不自然,因为它远离了模型的训练范围。另外在处理下游任务时,与原始训练任务之间的差异可能造成一些挑战。
格式的不同:
自然语言推理(NLI): 下游任务如
NLI涉及两个句子的比较,以产生单一的二进制输出。这与语言模型通常用于生成下一个标记或填充MASK标记的任务截然不同。例如,
NLI的逻辑推理过程涉及多层次的比较和理解,而不仅仅是根据给定的上下文生成下一个可能的词。BERT 训练与 MASK 标记:
BERT训练过程中使用了MASK标记,而许多下游任务可能并不使用这些标记。这种不同可能导致在针对具体任务时需要对模型进行显著的调整。
主题转变:
特定领域的需求: 下游任务可能集中在特定的主题或领域上。
例如医疗记录分析或法律文档解析。这些任务可能涉及专门的术语和知识,与模型的通用训练任务相去甚远。
广泛主题的灵活性: 语言模型可能需要处理各种不同的主题。
如果下游任务突然聚焦在一个新的或非常独特的领域上,这可能会超出模型的训练范围。
时间转变:
新知识的需求: 随着时间的推移,新的信息和知识不断涌现。
例如,
GPT-3在拜登成为总统之前就已训练完毕,因此可能缺乏有关他总统任期的最新信息。非公开信息的需求: 有时下游任务可能涉及在训练期间不公开的信息。
这可能需要更多特定领域的专业知识和调整。
10.2 通用的 adaptation 配置
下面提供使用预训练语言模型(LM)的参数来适配(adapt)下游任务的一般设置。
预训练语言模型(Pre-trained LM): 在适配阶段的开始,我们已经有了一个预训练的语言模型,用参数 θLM 表示。这个模型被训练来理解和生成语言,但不是特别针对任何特定任务。
下游任务数据集(Downstream Task Dataset): 我们获得了一组来自下游任务分布 P_{task} 的样本数据。这些数据可以是文本分类、情感分析等任务的特定实例,每个样本由输入 x 和目标输出 y 组成,如:\left(x^{(1)}, y^{(1)}\right), \ldots,\left(x^{(n)}, y^{(n)}\right)。
适配参数(Adaptation Parameters): 为了使预训练的
LM适合特定的下游任务,我们需要找到一组参数 \gamma,这组参数可以来自现有参数的子集或引入的新的参数,\Gamma。这些参数将用于调整模型,以便它在特定任务上的表现更好。任务损失函数(Task Loss Function): 我们需要定义一个损失函数 \ell_{\text {task }} 来衡量模型在下游任务上的表现。例如,交叉熵损失是一种常见的选择,用于衡量模型预测的概率分布与真实分布之间的差异。
优化问题(Optimization Problem): 我们的目标是找到一组适配参数 \gamma_{\text {adapt }},使得任务损失在整个下游数据集上最小化。数学上,这可以通过以下优化问题表示:
\gamma_{\text {adapt }}=\operatorname{argmin}_{\gamma \in \Gamma} \frac{1}{n} \sum_{i=1}^n \ell_{\text {task }}\left(\gamma, \theta_{\mathrm{LM}}, x_i, y_i\right) .
通过这个过程,我们可以取得一组适配参数 \gamma_{\text {adapt }},用于参数化适配后的模型p_{adapt}。这样,我们就可以将通用的、任务无关的预训练语言模型适配到特定的下游任务上,以实现更好的性能。
这种适配方法将模型的通用性与特定任务的效能结合在一起,既保留了模型的灵活性,又确保了在特定任务上的高效表现。
当前主流的几种 Adaptation 方法:
- Probing
- Fine-tuning
- Lightweight Fine-tuning
10.3 总体总结
在实际应用过程中,需要将大型语言模型适配到各种不同的下游任务中,这些任务可能与语言建模有很大不同。
- 探测法(Probing):探测法在冻结的语言模型之上训练一个特定任务的预测头,将语言模型视为良好的表示提取器。冻结语言模型倾向于限制该方法的表现能力。
- 微调(Fine-tuning):微调将大型语言模型参数视为下游任务的进一步训练的初始化,这比探测更具表现力,但也更昂贵,因为我们必须为每个下游任务保存整个模型。
- 轻量级微调(Lightweight fine-tuning):轻量级微调在微调和探测之间取得了平衡,只优化少量参数(模型的<1%),但它优化了模型的高杠杆部分,因此仍然非常具有表现力。 通过上述方法,可以更灵活地应对各种不同的下游任务,既实现了对特定任务的精确适配,又在一定程度上控制了计算和存储的成本,从而在实际应用中取得更好的性能和效率。
10.4 Reference
Multitask Prompted Training Enables Zero-Shot Task Generalization. Victor Sanh et al.. 2021. Introduces T0 from BigScience.
Finetuned Language Models Are Zero-Shot Learners. Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, Quoc V. Le. 2021. Introduces FLAN from Google.
Prefix-Tuning: Optimizing Continuous Prompts for Generation. Xiang Lisa Li, Percy Liang. ACL/IJCNLP 2021.
Training language models to follow instructions with human feedback.Long Ouyang et al.. InstructGPT paper.
The Power of Scale for Parameter-Efficient Prompt Tuning, Brian Lester, Rami Al-Rfou, Noah Constant. EMNLP 2021. Introduces prompt tuning.
Towards a Unified View of Parameter-Efficient Transfer Learning, Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, Graham Neubig. ICLR 2022.
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks, Xiao Liu et al. arXiv 2021.
11. 环境影响
本章讨论一个问题:大语言模型对环境的影响是什么?
这里给出的一个答案是:气候变化
一方面,我们都听说过气候变化的严重影响 (Paper 1、Paper 2):
- 我们已经比工业革命前的水平高出1.2°C
- 需要保持在1.5°C以下以避免气候危机
- 根据目前的轨迹,在未来几十年内将达到2.7°C
另一方面,我们看到训练大语言模型所需的计算量大幅增加(从而导致二氧化碳排放)。以下是一些数据:
- Strubell et al., 2018 估计,训练排放了626,000磅二氧化碳(5辆汽车终生的排放量)。
- DeepMind的 Gopher 报告称,训练产生的二氧化碳估计为380吨。
本章将学习如何将大语言模型与环境影响联系起来。
11. 1 Introduction
学习目标:
- 全面了解大语言模型对环境的影响。
- 能够计算训练特定语言模型产生的排放量。
- 提高对监测和减轻(负面)环境影响的认识,甚至承担个人责任。
注意事项:
- 本章的重点是了解(环境)成本。
- 大语言模型大幅提升了效果,但是需要考虑成本。如何权衡(trade-off)非常具有挑战性。
- 与此同时,世界人口的收益和成本往往非常不均衡,成本“不成比例地落在穷人和弱势群体身上”。
- 所提供的所有数字都是估计,因为:
- 缺乏对数据中心的监控和信息
- 这些信息通常是私有的
- 很难用摊余成本进行信用/责任分配(例如,建立数据中心+训练多个模型,训练一个模型+使其适配许多下游任务)。
11.2 生命周期评估
本节主要基于 Ligozat
et al. (2021) 的论文,从多个角度进行探讨语言模型 AI
对气候影响的内容:
从哲学角度来说,大多数关于人工智能和机器学习对环境影响的工作都集中在温室气体排放(受气候变化启发)上,但更重要的是(尽管很难)采取系统方法来思考:
对环境的全面影响(排放、水足迹)
IT设备的整个生命周期(例如,生产、使用、寿命终止)
从生命周期评估(LCA)的角度来说:
生命周期评估(LCA)(ISO 14040和14044)为实现这一点提供了一个框架。
需要“从系统的角度”来避免“一个问题的解决方案会产生几个新的、经常被忽视的问题”。
从IT设备的生命周期来说:
生产:
- 原材料提取:提取矿石以及转化为金属的所有过程
- 制造:包括制造设备的所有过程
- 运输:设备运输过程
使用:设备的实际能耗
寿命终止:拆除、回收/处置设备
从环境影响的角度来说:
其他二阶效应(更多细节):
\text{language model} \quad\Rightarrow\quad \text{compute} \quad\Rightarrow\quad \text{energy use} \quad\Rightarrow\quad \text{greenhouse gas emissions} \quad\Rightarrow\quad \text{environmental impact}
11.3 气候变化
虽然考虑整个生命周期很重要,但我们将主要关注气候变化和温室气体排放,因为这是大部分研究人工智能和机器学习对环境的影响所关注的。
气温正在上升:
- 自1900年以来,平均表面温度增加了2.14˚F(1.19˚C)。
- 自2005年以来,出现了10个最热年份。
- 温度随时间增加。
负面影响:
- 自然灾害增加(极端热浪、洪水、干旱、野火)
- 海平面上升破坏沿海社区和野生动物生态系统
原因:
人类活动加速:
- 燃烧化石燃料(煤、石油、天然气)发电、制造、运输(汽车、卡车、船舶、飞机)
- 种植作物(肥料)
- 砍伐森林(例如,建立农场)
11.4 能源使用和温室气体排放
到目前为止,我们已经讨论了温室气体排放及其对气候变化的影响,气候变化是环境影响的一种特别突出的形式。数据中心使用能源(以电力的形式)。这是如何映射到排放量上的?答案是,这取决于电力是如何产生的。
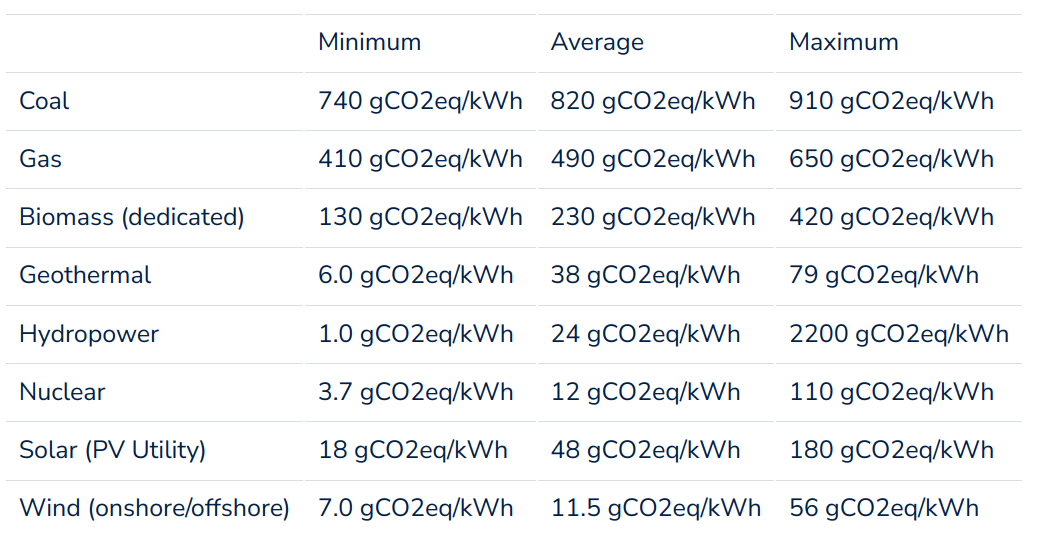
碳强度(Carbon intensity:):使用每千瓦时能源排放的碳量(来源)
化石燃料(煤、天然气)产生的排放量最多(来自直接排放)
如果考虑到整个生命周期(发电厂建设、采矿、废物管理),其他绿色能源(太阳能、风能)也会产生排放
在魁北克运行同样的任务(水电)的排放量将比爱沙尼亚(煤炭)少30倍
数据中心统计数字 (Md Abu Bakar Siddik et al., 2021):
- 2018年,全球数据中心用电量为2050亿千瓦时(占总用电量的1%)。
- 在美国,2014年数据中心用电量占总用电量的1.8%。
- 30%的数据中心位于美国。
- 美国温室气体排放总量的0.5%来自于于数据中心。
- 好消息:从2010年到2018年,计算量增加了550%,但电力消耗仅增加了6%(由于能源效率的提高)。
11.5 估算训练模型的排放量
现在让我们试着计算训练所需的能源使用量,从而计算温室气体排放量。
- ML CO2 Impact Calculator
ML CO2 Impact Calculator(Lacoste et al., 2019)提供了一种基于硬件、使用的小时数、供应商和地区来估计排放量的简单方法。
-
计算功耗(kWh):
- p_\text{cpu}:CPU的平均功率(W)
- p_\text{gpu}:GPU的平均功率(W)
- p_\text{dram}:DRAM的平均功率(W)
- \text{PUE}:用电效率:提供给数据中心的总功率/IT设备消耗的功率
\text{emissions} = R_{\text{power} \to \text{emit}} \text{PUE} (p_\text{cpu} + p_\text{gpu} + p_\text{dram})
平均值:
\text{PUE}=1.58(2018年全球数据中心平均值)
R_{\text{power} \to \text{emit}}=0.954(2018年平均排放量-磅/千瓦时)
结果
BERT-base(110M参数):1438 lbs CO2eq
NVIDIA在64个V100 GPU上训练79.2小时
神经结构搜索(213M参数)以获得Evolved Transformer So et al. (2019):626155 lbs CO2eq
1名乘客乘坐从纽约到旧金山的往返航班:1984 lbs CO2eq(0.9吨)
汽车生命周期:126,000 lbs CO2eq
-
简单形式: \text{emissions} = R_{\text{power} \to \text{emit}} (\text{energy-train} + \text{queries} \cdot \text{energy-inference})
- NVIDIA:80%的ML工作负载是推理,而不是训练
许多设计决策:
模型架构:Transformer与Evolved Transformer
处理器:NVIDIA的P100与Google的TPU
数据中心:平均(1.58)与谷歌(1.11)
能源供应组合(如煤炭、水电):平均(0.429千克二氧化碳/千瓦时)与谷歌(0.080千克二氧化碳/千瓦时)
- 注:总额为0.478,净额为0.080
- 扣除出售给其他公司的清洁能源
11.6 总体总结
环境影响是一个巨大的话题。一切都是相互联系的,很难得出一个干净的定量指标。但要真正着眼于全局。
尽管如今大语言模型的还很少,但它正在快速增长。
大语言模型的通用性提供了节省成本的潜力(“一次性训练”并适用于许多不同的任务)。但它们的成本要高得多,需要可能需要重新训练。这里的权衡是什么?
缓解措施:
- 尝试在使用清洁能源的数据中心训练模型
- 碳抵消的效果各不相同(森林种植活动产生单一种植)
- 更高效的模型架构、训练程序、硬件(但要注意反弹效应)
在论文报告排放量:
- 可以提高认识(想象一下,如果每一篇论文都能报告排放量)
- 调整激励(人们目前关注准确性,但碳排放也很重要!)
11.7 Reference
推荐的Python包
通用信息
Energy and Policy Considerations for Deep Learning in NLP. Emma Strubell, Ananya Ganesh, A. McCallum. ACL 2019.
Quantifying the Carbon Emissions of Machine Learning. Alexandre Lacoste, Alexandra Luccioni, V. Schmidt, Thomas Dandres. 2019. Introduces ML Carbon Emissions Calculator.
Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning. Peter Henderson et al. 2020. Introduces the environment impact tracker tool.
Carbon Emissions and Large Neural Network Training. David Patterson, Joseph Gonzalez, Quoc V. Le, Chen Liang, Lluís-Miquel Munguía, D. Rothchild, David R. So, Maud Texier, J. Dean. 2021. From Google.
Sustainable AI: Environmental Implications, Challenges and Opportunities. Carole-Jean Wu, R et al. 2021. From Facebook.
Unraveling the hidden environmental impacts of AI solutions for environment. Anne-Laure Ligozat, J. Lefèvre, A. Bugeau, Jacques Combaz. 2021.
The environmental footprint of data centers in the United States.