6. 模型架构
6.1 大模型之模型概括
语言模型可以被看做是一个黑箱,当前大规模语言模型的能力在于给定一个基于自身需求的prompt 就可以生成符合需求的结果。
语言模型的形式可以表达为:
从数学的角度考虑就对训练数据 (traing data: )的概率分布:
本章将讨论大型语言模型的构建,主要讨论两个主题,分别是分词和模型架构:
-
分词:将字符串拆分成多个标记。
-
模型架构:主要讨论
Transformer架构,这是真正实现大型语言模型的建模创新。
6.2 分词
6.2.1 基于空格的分词
最简单的解决方案是使用 text.split(' ') 方式进行分词,这种分词方式对于英文这种按照空格,且每个分词后的单词有语义关系的文本是简单而直接的分词方式。
然而,空格来划分单词会带来很多问题:
-
对于一些语言,如中文,句子中的单词之间没有空格:
1
"我今天去了商店。"
-
还有一些语言,比如德语,存在着长的复合词(例如Abwasserbehandlungsanlange)。
-
英语的连字符词(例如father-in-law)和缩略词(例如don’t)等也需要被正确拆分。
例如,Penn Treebank将don’t拆分为do和n’t,这是一个在语言上基于信息的选择,但不太明显。
那么,什么样的分词才是好的呢?目前从直觉和工程实践的角度来说:
- 不希望有太多的标记(极端情况:字符或字节),否则序列会变得难以建模。
- 不希望标记过少,否则单词之间就无法共享参数(例如,mother-in-law 和 father-in-law 应该有着相似的特征)。
- 每个标记应该是一个在语言或统计上有意义的单位。
例子:
- [th, e, (th 出现了 3次)
- [the, , [the, the, (the 出现了 3次)
- [the, the, the, (ca 出现了 2次)
6.2.2 Byte pair encoding
将字节对编码(BPE)算法应用于数据压缩领域,用于生成其中一个最常用的分词器。BPE 分词器需要通过模型训练数据进行学习,获得需要分词文本的一些频率特征。
学习分词器的过程,直觉上,我们将每个字符作为自己的标记,并组合那些经常共同出现的标记。整个过程可以表示为:
- 输入:训练语料库(字符序列)。
- 初始化词汇表 为字符的集合。
- 当我们仍然希望 继续增长时:
找到 中共同出现次数最多的元素对 。 - 用一个新的符号 替换所有 的出现。将
- 添加到 中。
Unicode的问题:
Unicode(统一码)是当前主流的一种编码方式。考虑到 Unicode 字符非常多(共144,697个字符),在训练数据中我们不可能见到所有的字符。因此我们可以借助 BPE 算法对字节而不是 Unicode 字符,来减少数据的稀疏性 (Wang et al., 2019)。
以中文为例:
BPE 算法在这里的作用是为了进一步减少数据的稀疏性。通过对字节级别进行分词,可以在多语言环境中更好地处理Unicode字符的多样性,并减少数据中出现的低频词汇,提高模型的泛化能力。通过使用字节编码,可以将不同语言中的词汇统一表示为字节序列,从而更好地处理多语言数据。
6.2.3 Unigram model (SentencePiece)
与仅仅根据频率进行拆分不同,一个更“有原则”的方法是定义一个目标函数来捕捉一个好的分词的特征,这种基于目标函数的分词模型可以适应更好分词场景,Unigram model就是基于这种动机提出的 (Kudo, 2018)。
这是 SentencePiece 工具 (Kudo&Richardson, 2018) 所支持的一种分词方法,与 BPE 一起使用。它被用来训练 T5 和 Gopher 模型。给定一个序列 ,分词器 是:
的一个集合。
这边给出一个实例:
- 训练数据(字符串):
- 分词结果 (其中)
- 似然值:
在这个例子中,训练数据是字符串""。分词结果 表示将字符串拆分成三个子序列:。词汇表 $ V={𝖺𝖻,𝖼}$ 表示了训练数据中出现的所有词汇。
似然值 $p(x_{1:L}) $ 是根据 unigram 模型计算得出的概率,表示训练数据的似然度。在这个例子中,概率的计算为 。这个值代表了根据 unigram 模型,将训练数据分词为所给的分词结果 的概率。
unigram 模型通过统计每个词汇在训练数据中的出现次数来估计其概率。在这个例子中, 在训练数据中出现了两次,$𝖼 $ 出现了一次。因此,根据 unigram 模型的估计,
\begin{align*} p(𝖺𝖻)&=2/3,\\ p(𝖼)&=1/3 \end{align*}
通过将各个词汇的概率相乘,我们可以得到整个训练数据的似然值为 。
似然值的计算是 unigram 模型中重要的一部分,它用于评估分词结果的质量。较高的似然值表示训练数据与分词结果之间的匹配程度较高,这意味着该分词结果较为准确或合理。
算法流程
- 从一个“相当大”的种子词汇表 开始。
- 重复以下步骤:
- 给定 ,使用
EM算法优化 和 。 - 计算每个词汇 的 ,衡量如果将 从 中移除,似然值会减少多少。
- 按照 进行排序,并保留 中排名靠前的 的词汇。
- 给定 ,使用
这个过程旨在优化词汇表,剔除对似然值贡献较小的词汇,以减少数据的稀疏性,并提高模型的效果。通过迭代优化和剪枝,词汇表会逐渐演化,保留那些对于似然值有较大贡献的词汇,提升模型的性能。
6.3 模型架构
到目前为止,我们已经将语言模型定义为对标记序列的概率分布 。
接下来介绍上下文向量表征 (Contextual Embedding),主要的关键发展是将标记序列与相应的上下文的向量表征:
正如名称所示,标记的上下文向量表征取决于其上下文(周围的单词);例如,考虑 mouse 的向量表示需要关注到周围某个窗口大小的其他单词。
-
符号表示:我们将 定义为嵌入函数(类似于序列的特征映射,映射为对应的向量表示)。
-
对于标记序列 , 生成上下文向量表征 。
6.3.1 语言模型分类
对于语言模型来说,最初的起源来自于 Transformer 模型,这个模型是编码-解码端 (Encoder-Decoder)的架构。但是当前对于语言模型的分类,将语言模型分为三个类型:
- 编码端(Encoder-Only):
BERT、RoBERTa等; - 解码端(Decoder-Only):
GPT系列模型; - 编码-解码端(Encoder-Decoder):
Transformer、BART、T5等模型。
6.3.2 语言模型理论
接下来介绍语言模型的模型架构,此处主要介绍 Transformer 架构 (Vaswani et al.,2017):
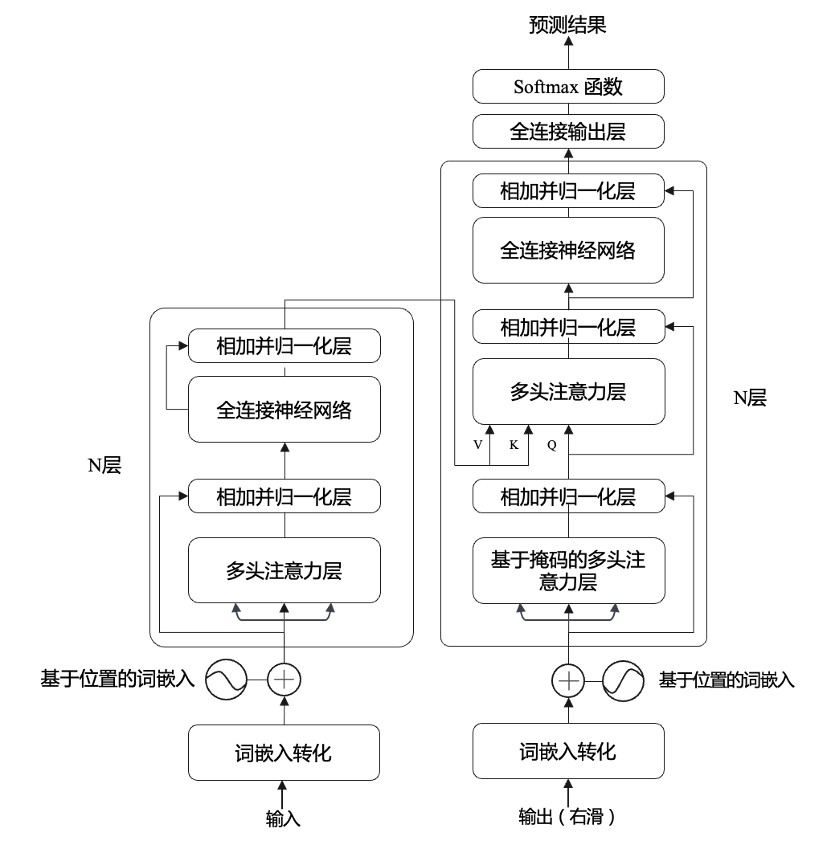
从上图可知,Transformer 模型的左右两侧分别是基础的编码器(Encoder)和解码器(Decoder)单元,两者共同组合构成了一个Transformer 层。主要部分介绍如下:
- 输入:模型的训练不要求输入和输出数据的长度相同,当两者长度不相同时,将空缺部分填充为零向量(
pad)。 - 输出(右滑):在文本摘要任务中,模型训练的目的是为了预测下一个字符的概率,从而保持输入和输出的数据长度相同,这时输出的结果可以视为相对于输入序列往右移了一个单位,即右滑。
- 基于位置的词嵌入:借助正弦曲线对单词在文本中的相对位置进行建模。在语言模型的构建中,词的顺序会对句子的语义产生影响,因此Transformer模型中增加了词的位置信息,即基于位置的词嵌入。所以编码器的输入是输入词嵌入和对应位置的嵌入信息的组合。
- 多头注意力层:图4中的每个多头注意力层下方都传进3个并列的箭头,它们分别表示Value()、Key()和Query()。编码器的每一层使用线性变化处理隐藏状态,分化出Key和Value传递给解码器的多头注意层。
- 层:Transformer模型的深度通常为6层,在每一层的末端,编码器与解码器会将隐藏状态传递给下一层。
- 全连接前馈神经网络:对不同位置的词嵌入信息进行变换,使得其在任务上下游中的维度统一。
- 相加并归一化层:将上一层的输入数据与输出数据进行相加,形成残差结构并进行归一化处理。
- 全连接输出层:以概率分布的形式输出模型的结果。
Transformer 是真正推动大型语言模型发展的序列模型。正如之前所提到的,Transformer模型将其分解为Encoder-Only(GPT-2,GPT-3)、Decoder-Only(BERT,RoBERTa)和Encoder-Decoder(BART,T5)模型的构建模块。
关于Transformer的学习资源有很多:
- Illustrated Transformer和Illustrated GPT-2:对Transformer的视觉描述非常好。
- Annotated Transformer:Transformer的Pytorch实现。
Transformer 的关键技术:
- 注意力机制
- 残差连接和归一化
- 位置嵌入
6.4 Reference
分词:
- Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP. Sabrina J et al. 2021. Comprehensive survey of tokenization.
- Neural Machine Translation of Rare Words with Subword Units. Rico Sennrich, B. Haddow, Alexandra Birch. ACL 2015. Introduces byte pair encoding into NLP. Used by GPT-2, GPT-3.
- Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. Yonghui Wu, M et al. 2016. Introduces WordPiece. Used by BERT.
- SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. Taku Kudo, John Richardson. EMNLP 2018. Introduces SentencePiece.
模型架构:
- Language Models are Unsupervised Multitask Learners. Introduces GPT-2.
- Attention is All you Need. Ashish Vaswani et al. NIPS 2017.
- Illustrated Transformer
- CS224N slides on RNNs
- CS224N slides on Transformers
- Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. Ofir Press, Noah A. Smith, M. Lewis. 2021. Introduces Alibi embeddings.
- Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. Zihang Dai et al. ACL 2019. Introduces recurrence on Transformers, relative position encoding scheme.
- Generating Long Sequences with Sparse Transformers. R. Child, Scott Gray, Alec Radford, Ilya Sutskever. 2019. Introduces Sparse Transformers.
- Linformer: Self-Attention with Linear Complexity. Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma. 2020. Introduces Linformers.
- Rethinking Attention with Performers. K. Choromanski et al. ICLR 2020. Introduces Performers.
- Efficient Transformers: A Survey. Yi Tay, M. Dehghani, Dara Bahri, Donald Metzler. 2020.
Decoder-only 架构:
- Language Models are Unsupervised Multitask Learners. Alec Radford et al. 2019. Introduces GPT-2 from OpenAI.
- Language Models are Few-Shot Learners. Tom B. Brown et al. NeurIPS 2020. Introduces GPT-3 from OpenAI.
- Scaling Language Models: Methods, Analysis&Insights from Training Gopher. Jack W et al. 2021. Introduces Gopher from DeepMind.
- Jurassic-1: Technical details and evaluation. Opher Lieber, Or Sharir, Barak Lenz, Yoav Shoham. 2021. Introduces Jurassic from AI21 Labs.
Encoder-only 架构:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. NAACL 2019. Introduces BERT from Google.
- RoBERTa: A Robustly Optimized BERT Pretraining Approach. Yinhan Liu et al. 2019. Introduces RoBERTa from Facebook.
Encoder-decoder 架构:
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. M. Lewis et al. ACL 2019. Introduces BART from Facebook.
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Colin Raffel et al. J. Mach. Learn. Res. 2019. Introduces T5 from Google.