4. 大模型的数据
在之前的内容,我们讨论了大型语言模型的行为(能力和损害),本节将开始讨论模型的构建。我们知道,任何机器学习方法的起点都是训练数据。
4.1 大语言模型背后的数据
为了训练大型语言模型,通常会使"原始文本"尽可能多地涵盖广泛的领域、类型、语言。
-
一个非营利组织,它对网络进行爬取,并提供免费给公众的快照。由于其便利性,它已经成为许多模型如 T5、GPT-3 和 Gopher 的标准数据源。例如,Common Crawl 在2021年4月的快照就有 320TB 的数据,这比谷歌的索引小了好几个数量级。
尽管网络数据丰富,但存在一些局限性 (Bender et al., 2021):
-
全球性失衡;
-
发达国家用户为主;
-
GPT-2的训练数据基于 Reddit,美国Reddit用户中有67%是男性,64%的年龄在18到29岁之间 (皮尤互联网研究调查,2016)。 -
维基百科的编者中只有8.8-15%是女性。
-
网络上的骚扰可能会让某些人群(如跨性别者、神经发育不同的人)产生排斥感。
-
过滤"不良词汇"可能进一步边缘化某些人群(如LGBT+)。
-
因此,我们的结论是:理解和记录用于训练大型语言模型的数据集的组成是至关重要的。
4.1.1 WebText and OpenWebText dataset
创建WebText的过程包括:抓取至少获得3个赞的所有外链,过滤掉维基百科以便在基于维基百科的基准测试中进行评估,最终得到了40GB的文本。
OpenWebText数据集 在理念上复制了WebText的构建方法,目的是尽可能地模拟和复现WebText的数据特性和结构。这样,研究者就可以利用 OpenWebText 来进行一些原本需要WebText 数据集的实验和研究。
- OpenWebText 从 Reddit提交的数据集 中提取所有URL,使用Facebook的 fastText 过滤掉非英语内容,删除近乎重复的内容,最终得到了38GB的文本。
4.1.2 Colossal Clean Crawled Corpus(C4)
C4语料库 被用来训练 T5 模型。这个语料库从2019年4月的 Common Crawl 快照(1.4万亿个标记)开始,通过数据清洗之后,最终得到了 806GB 的文本(1560亿个标记)。
Dodge等人在2021年对C4数据集进行了深入分析。分析主要涉及以下几个方面:
- 元数据:来源,话语数据。
- 包含的数据:由机器或人类创作的,社会偏见,数据污染。
- 排除的数据:医疗或健康数据,人口身份。
4.1.3 Benchmark的数据污染问题
一般而言,在机器学习中,保证训练数据和测试数据的分离(我们称之为数据卫生)相对容易。但对于大型语言模型,训练数据和基准数据都源自互联网,要事先保证它们的完全分离就显得有些困难。
以 XSum摘要 数据集为例,输入的是一段关于一个前阿森纳门将的介绍,而输出则是这位门将被任命为技术主管的新闻,细节如下面的例子。这就存在两种类型的污染。
-
输入和输出污染,即输入和输出都出现在训练数据中,其比例在 至 之间。
-
输入在训练数据中出现,比如来自维基百科的QNLI数据集,这种污染的比例在 至 之间。
例如:
- Input: The 48-year-old former Arsenal goalkeeper played for the Royals for four years. He was appointed youth academy director in 2000 and has been director of football since 2003. A West Brom statement said: “He played a key role in the Championship club twice winning promotion to the Premier League in 2006 and 2012.
Output: West Brom have appointed Nicky Hammond as technical director, ending his 20-year association with Reading.
此外,我们还要注意,这种数据污染并不是由于数据集的托管方式导致的,因为数据集通常会以JSON文件的形式存储,而不是网页。
4.1.4 GPT-3 的数据集
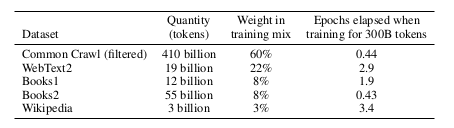
GPT-3的数据集主要源自 Common Crawl,而 Common Crawl 又类似于一个参考数据集——WebText。
GPT-3 通过训练一个二元分类器来预测 WebText 与 Common Crawl 的区别。如果预测文档更接近 WebText,那么这个文档就有更大的概率被保留。在处理数据时,GPT-3 采用了模糊去重的方法(检测13-gram重叠,如果在少于10个训练文档中出现,则移除窗口或文档),并从基准数据集中移除了数据。此外,GPT-3 也扩大了数据来源的多样性(包括 WebText2、Books1、Books2 以及维基百科)。在训练过程中,Common Crawl 被降采样,它在数据集中占 82%,但只贡献了 60% 的数据。
4.1.5 The Pile数据集
然而,GPT-3也暗示了我们除了网络爬虫之外,也许还可以寻找其他更高质量的数据来源。EleutherAI(一个致力于构建开放语言模型的非营利组织)进一步推动了这个想法。他们发布了一种语言模型的数据集,名为The Pile,其核心理念是从较小的高质量数据源(如学术和专业资源)中获取数据。
该数据集包含了 825GB 的英文文本,由22个高质量数据集组成。当用这个数据集训练 GPT-2 Pile(1.5B参数)并与用GPT-3数据集训练的GPT-3(175B参数)进行比较时,研究者们发现,The Pile包含了大量GPT-3数据集未能很好覆盖的信息。他们还分析了贬损内容、性别/宗教偏见等问题,结果与以前的研究大致相同。
4.2 数据集文档
在本文中,我们将深入探讨数据的一般原则,暂时不讨论语言模型数据集的具体内容。长期以来,人们都明白文档记录的重要性,然而在机器学习领域,这个过程往往被处理得较为随意。Gebru et al. (2018)在2018年发表的论文深刻影响了这一领域,他们提出了围绕文档的社区规范。Bender & Friedman (2018) 在2018年的论文《数据声明》也提出了一个更适用于语言数据集的框架,这两个工作都在强调透明度。
数据文档的主要目的有两个:
- 让数据集的创建者有机会反思他们的决策,以及在创建数据集过程中可能产生的潜在危害,比如社会偏见;
- 让数据集的使用者了解何时可以使用数据集,何时不应使用数据集。
在整个数据集的生命周期中,我们需要考虑很多问题,比如:
- 创建动机:谁是数据集的创建者,数据集的创建是由谁资助的;
- 组成部分:数据集中的实例代表什么,是否有缺失信息,是否包含机密数据等;
- 数据收集:每个实例的数据是如何获取的,谁参与了数据收集,他们是如何获得报酬的,以及是否进行了道德审查等;
- 预处理、清理和标记:这些工作是否已经完成,是否有相应的软件可供使用;
- 数据使用:数据集是否已经被用于某些任务,是否有不适合使用该数据集的任务;
- 分发阶段:数据集将如何分发,是否有第三方对数据施加了知识产权或其他的限制;
- 维护阶段:谁会负责维护数据集,数据集是否会更新。
专门针对自然语言处理(NLP)数据集的工作,比如数据声明,还涵盖了其他方面,例如策划理念,语言多样性,说话人和注释者的人口统计学信息等。
5. 大模型法律
5.1 简介
在这个教程中,我们将探讨法律对大型语言模型的开发和部署有何规定。我们将会按照以下的步骤进行讨论:
-
新技术与现有法律的关系
-
互联网的独特挑战
-
法律与道德的区别
-
法律的管辖权问题
-
法律的类型
-
大型语言模型
-
数据
-
应用
5.2 版权法
大型语言模型或任何机器学习模型,都是基于数据进行训练的,而这些数据是人类劳动的结果(例如,作者,程序员,摄影师等)。除了创作者外,其他人可以对这些创作(例如,书籍,代码,照片等)进行何种使用,属于知识产权法的范畴。
- 知识产权法
动机是鼓励创建各种类型的知识产品。如果任何人都可以利用你的辛勤劳动并从中获利,人们就会对创造或分享失去动力。知识产权包括:版权,专利,商标,商业秘密。
- 许可
许可(来自合同法)是由许可人授予许可使用者的。实际上,“许可就是承诺不起诉”。创作共享许可,允许免费分发版权作品。
-
公平使用(第107条)
自1840年代以来,公平使用一直是普通法。决定是否适用公平使用的四个因素是:
- 使用的目的和性质(教育用途优于商业用途,转型用途优于复制);
- 版权作品的性质(虚构作品优于事实作品,创新性的程度);
- 使用的原作部分的数量和实质性;和
- 使用对原作市场(或潜在市场)的影响。
5.3 公平学习与机器学习
公平学习主张机器学习属于公平使用。机器学习系统的数据使用是变革性的,它不会改变作品,但会改变目的。
-
将机器学习视为公平的论据:训练数据的广泛访问会为社会创造更好的系统。如果不允许使用,那么大部分作品无法用来产生新的价值。
-
将机器学习视为不公平的论据:机器学习系统不会产生创意的“最终产品”,而只是赚钱。生成模型(例如,语言模型)可以与创意专业人士竞争。
在版权法下,很难分离可保护的(例如,表达)和不可保护的(例如,想法)。
5.4 隐私法律教程
5.5 法律条例
-
加利福尼亚的机器人披露法案:
如果使用机器人与人进行通信,而不披露它是一个机器人,这是违法的。限制:只适用于激励销售或影响选举投票的情况。限制:只适用于每月在美国有1000万访问者的公开网站。
5.6 总结
在我们训练大型语言模型时,必须面对版权和公平使用的问题。由于网络爬取的未筛选性质,你必须诉诸公平使用(从每个人那里获得许可证将非常困难)。模型的生成性可能会对争论公平使用提出挑战(可以与人类竞争)。在什么水平上进行调控(语言模型还是下游应用)是有意义的?这个领域正在迅速发展,需要深入的法律和人工智能专业知识才能做出明智的决定!