1. Introduciton
1.1 Job description
本项目为京东评论数据爬虫。随着电子商务的发展,有如京东、淘宝等网站,在线评论作为电子口碑显著影响着产品的营销策略。
商品评论文本具有如下特点:
- 短文本。商品评论的文本一般比较简短,大部分包括用户对产品整体的评论,也包括用户对喜欢的商品属性的评价。以手机产品为例,包括“系统不错啊”、“屏幕非常清晰”、“外观时尚大气”等等的评价;
- 情感倾向明显。商品评论是针对产品整体或属性进行评价,这样是商品评论文本有着很明显的情感倾向,如“喜欢”、“差”等;
- 数据量大。电子商务网站的交易量非常大,网上的评论数据以秒为单位的速度不断的刷新,增大。面对无限大的数据,通常在分析是取一段时间内旳文本进行分析,即可获得相对全面的产品评论信息;
- 不规范性。语法不规范,口语化严重是互联网语言的一大特点,而且包含很多时下流行词汇。例如“木有”代表没有,“撒米”代表什么等等。口语化严重还包括出现很多新鲜的词汇,包括“坑爹”、“不明觉厉”、“我伙呆”等等。这些都给文本分析带来很多困难;
- 易获取性。商品评论信息比较容易获取,各大电子商务网站例如京东、淘宝、亚马逊等都提供,方便获取到评论信息。 本文所有涉及到的商品评论文本,均为京东商城牛肉产品的评论文本。
本研究中,以京东商城的生牛肉类产品为例子,爬取其评论信息。
1.2 Task analysis
首先,我们打开我们需要提取的商品链接(恒都牛腱子),打开开发者模式,可以发现其评论以
json 的形式进行存储,其链接的形式如下:https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=2925506&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1。因此我们可以通过爬取该地址进行评论的筛选和处理。
进一步分析可以发现,该链接所对应的评论页面主要由如下参数进行控制:
- productId:商品 id;
- score:评论星级数;
- page:评论页数;
了解这些信息之后,我们可以通过控制上面上个参数,用 loop
循环获取所有评论的数据。
1.3 Reviews analysis
热评
通过比对文本,我们可以发现热评信息在字段
hotCommentTagStatistics下,且仅有在page=1时,也就是说时在第一页评论中,才会出现热评,后面的页数不会出现热评。
Fig. 1 热评信息
用户评论
每个用户对商品的评论均保存在响应的字段中,如下图。读者可以根据连接中的字段和网页中的评论信息一一比对,此处便不再进行罗列。

Fig. 2 评论信息及其字段
2. Static crawler
由于评论信息均储存在 json
文件中,我们此处我们便使用静态爬虫进行爬取。
2.1 configuration
Load modules
1
2
3
4
5
6import re
import json
import time
import requests
import numpy as np
import pandas as pdRequest headers
1
2
3
4
5
6
7
8
9
10
11
12def get_head():
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh,zh-CN;q=0.9,en;q=0.8",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
return headers
2.2 Self-function
为了更为方便进行爬取,此处我们定义一些自定义函数。
请求网页
1
2
3
4
5
6
7
8def find_one_url(url):
try:
response = requests.get(url)
if response.status_code == 200: # 判断状态码 如果是200则请求成功
return response.text # 返回文档信息
return None
except RequestException: # 捕捉异常
return None得到
productiId1
2
3
4def get_product_id(url):
temp = url.split('.htm', 1)
item_id = temp[0].split('/')[-1]
return item_id得到
json文件的文本1
2
3
4
5
6
7
8
9
10def find_message(url, i):
r = requests.get(url, headers=get_head())
rtext = r.text
try:
jsondata=re.search('^[^(]*?\((.*)\)[^)]*$', rtext).group(1)
data = json.loads(jsondata)
print('解析第{}页成功!!!!'.format(i))
return data
except:
return -1
2.3 提取评论文本
2.3.1 数据界定
针对评论数据,我们主要爬取两部分数据:
商品热评
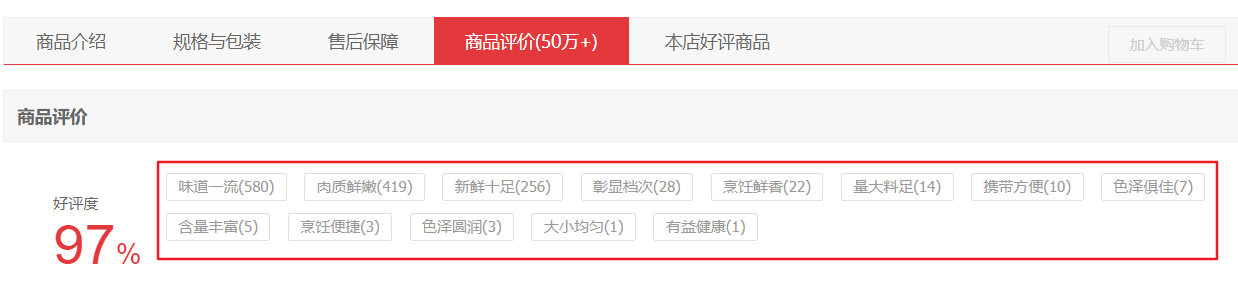
Fig. 3 热评信息
商品评论
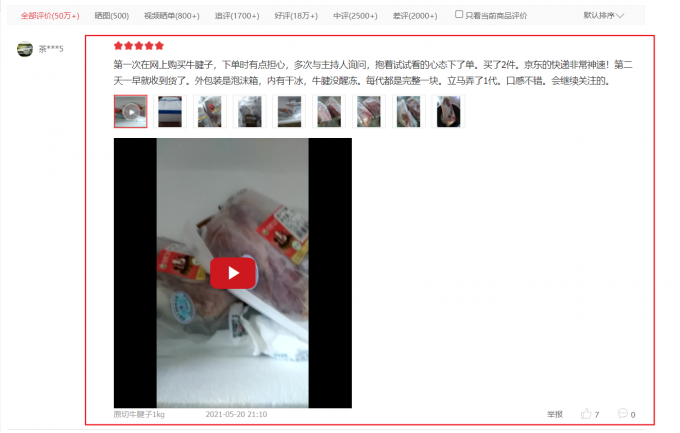
Fig. 4 评论信息
针对商品评论,我们会尽可能多的保留评论的信息,所以我们保存了如下信息:
id: 评论者的id;guid:评论的id;nickname:昵称;content:评论内容;creationTime:评论时间 ;score:评论星级;productColor:产品颜色;referenceName;videos_url:评论视频的链接;image_url:评论图片的链接;reply;回复;
最终期望得到成品如下:
- 商品热评
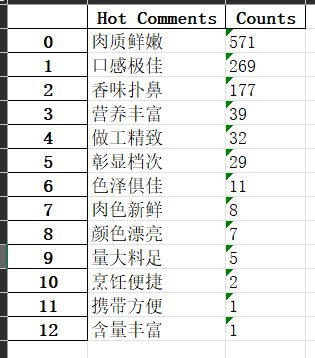
- 商品评论

2.3.2 定义爬取所需信息的函数
得到评论
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76def get_type_comments(url):
product_id = get_product_id(url)
pd_comments = pd.DataFrame()
pd_hot_comments = pd.DataFrame()
count = 0
for score in range(3, 8):
page = 0
print('---------score:{}---------------'.format(score))
while True:
start = pd_comments.shape[0]
comment_url = 'https://club.jd.com/comment/productPageComments.action?' \
'callback=fetchJSON_comment98&productId={}&score={}' \
'&sortType=5&page={}&pageSize=10&isShadowSku=0&rid=0&fold=1'
comment_url = comment_url.format(product_id, score, page)
# comment_url = comment_url.format(product_id, 5, page)
comment_detail = find_message(comment_url, page)
if comment_detail == -1:
break
else:
pass
comments = comment_detail['comments']
if page == 1 and score == 0:
# 提取热点评论
np_hot_comments = np.array(['Hot Comments', 'Counts'])
hot_comments = comment_detail['hotCommentTagStatistics']
for i in range(len(hot_comments)):
comment_name = hot_comments[i]['name']
count = hot_comments[i]['count']
np_hot_comments = np.vstack((np_hot_comments, np.array([comment_name, count])))
pd_hot_comments = pd.DataFrame(np_hot_comments[1:, :],
columns = np_hot_comments[0, :])
if len(comments) == 0:
break
else:
pass
for i in range(len(comments)):
need_keys = ['id', 'guid', 'nickname', 'content', 'creationTime', 'score',
'productColor', 'referenceName']
for key in need_keys:
pd_comments.loc[start+i, key] = comments[i][key]
if 'afterUserComment' in list(comments[i].keys()):
after_comments_info = comments[i]['afterUserComment']
pd_comments.loc[start+i, 'Zhuiping_content'] = after_comments_info['content']
pd_comments.loc[start+i, 'Zhuiping_time'] = after_comments_info['created']
if 'replies' in list(comments[i].keys()):
replies_info = comments[i]['replies']
length = len(replies_info)
if length != 0:
for i in range(length):
reply_info = replies_info[i]
pd_comments.loc[start+i, f'Reply_{i}_content'] = reply_info['content']
pd_comments.loc[start+i, f'Reply_{i}_time'] = reply_info['creationTime']
if 'images' in list(comments[i].keys()):
images_info = comments[i]['images']
for j in range(len(images_info)):
pd_comments.loc[start+i, f'IMG_url_{j}'] = images_info[j]['imgUrl']
if 'videos' in list(comments[i].keys()):
videos_info = comments[i]['videos']
for j in range(len(videos_info)):
pd_comments.loc[start+i, f'Video_mainpic_{i}'] = videos_info[j]['mainUrl']
pd_comments.loc[start+i, f'Video_url_{i}'] = videos_info[j]['remark']
count += 1
page += 1
if count <= 50:
time.sleep(1)
else:
count = 0
time.sleep(100)
return pd_comments, pd_hot_comments
2.4 开始爬取
考虑到我们的项目处理并不仅仅爬取一个网址,也需要多个商品的评论数据,因此,我们对主函数做一定的修改,使之不仅可以爬取单个商品的评论,也可以爬取多个商品的评论,并保存在不同的
csv 文件中。
单链爬取
1
2
3
4
5
6is_single = False
if is_single == True:
url = 'https://item.jd.com/2925506.html#comment'
pd_type_comments, pd_hot_comments = get_type_comments(url)
pd_type_comments.to_csv('./Comments_type_1.csv', encoding='ansi', errors = 'ignore')
pd_hot_comments.to_excel('./Hot_comments.xlsx', sheet_name = get_product_id(url))多链接爬取
在实际操作过程中,我们发现多链接爬取由于
request的次数太多,容易导致如下问题:ip容易被服务器暂时拉黑(大约半小时,可以换个网继续操作);- 容易达到端口的最大访问次数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20is_multi = True
if is_multi == True:
urls = ['https://item.jd.com/2925506.html#comment', 'https://item.jd.com/2925506.html',
'https://item.jd.com/100007810155.html', 'https://item.jd.com/2925346.html',
'https://item.jd.com/4924290.html', 'https://item.jd.com/6879534.html',
'https://item.jd.com/100006306997.html', 'https://item.jd.com/8543963.html',
'https://item.jd.com/100007212087.html', 'https://item.jd.com/5662044.html',
'https://item.jd.com/8543957.html', 'https://item.jd.com/6739532.html',
'https://item.jd.com/4607999.html', 'https://item.jd.com/100006930529.html',
'https://item.jd.com/100011848484.html']
for i in range(0, len(urls)):
print(f'----------正在爬取第{i}个网页的内容------------')
url = urls[i]
pd_type_comments, pd_hot_comments = get_type_comments(url)
uniq = pd_type_comments['content'].drop_duplicates().index
data_drop_dup = pd_type_comments.loc[uniq, :].reset_index()
data_drop_dup.to_csv(f'./Comments_type_product_{i}-0.csv', encoding='ansi', errors = 'ignore')
pd_hot_comments.to_excel(f'./Hot_comments_product_{i}.xlsx', sheet_name = get_product_id(url))
break
3 Dynamic crawler
3.1 Description
除了上述数据之外,我们还需要问答数据,其数据样式如下:
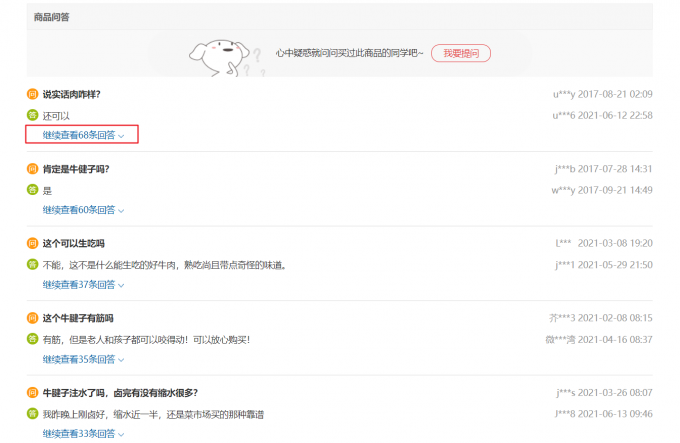
通过分析,可以发现其问答数据藏在 继续查看68条回答
按钮之下,通过点击可以动态加载数据,因此我们选择使用动态爬虫爬取问答数据。
3.2 爬取问答数据
1 | def get_ask_answers(url, pages): |
可以通过传入 url 和 pages
两个参数获取问答数据,如本案列中使用的参数如下:
url: https://item.jd.com/2925506.html#commentpages: 14
传入上述函数,最终可得到成品数据如下:

其中表头(第一行)为问题,其他行为该问题的回答。
4. Emotion analysis
接下来我们对得到的评论数据进行情感分析。
4.1 Preparation
4.1.1 Load data
1 | import numpy as np |
4.2 Preprocession
对数据进行预处理,在本次处理中,仅处理评论文本数据。
查看数据大小
1
data.shape
Results:
(32419, 44)
可以发现我们爬取的数据共有 44 列,其中图片和视频占大头。
Data description
1
data.info()
Results:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 32419 entries, 0 to 32418 Data columns (total 44 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Unnamed: 0 32419 non-null int64 1 id 29885 non-null float64 2 guid 32419 non-null object 3 nickname 32419 non-null object 4 content 32419 non-null object 5 creationTime 32419 non-null object 6 score 32419 non-null float64 7 productColor 30207 non-null object 8 referenceName 32419 non-null object 9 Video_mainpic_0 500 non-null object 10 Video_url_0 500 non-null object 11 Video_mainpic_1 492 non-null object 12 Video_url_1 492 non-null object 13 Video_mainpic_2 509 non-null object 14 Video_url_2 509 non-null object 15 Video_mainpic_3 476 non-null object 16 Video_url_3 476 non-null object 17 IMG_url_0 18849 non-null object 18 IMG_url_1 14269 non-null object 19 Video_mainpic_4 460 non-null object 20 Video_url_4 460 non-null object 21 Video_mainpic_5 500 non-null object 22 Video_url_5 500 non-null object 23 Video_mainpic_6 469 non-null object 24 Video_url_6 469 non-null object 25 IMG_url_2 9757 non-null object 26 Video_mainpic_7 533 non-null object 27 Video_url_7 533 non-null object 28 IMG_url_3 7876 non-null object 29 IMG_url_4 3474 non-null object 30 IMG_url_5 1780 non-null object 31 Video_mainpic_8 503 non-null object 32 Video_url_8 503 non-null object 33 Reply_0_content 739 non-null object 34 Reply_0_time 739 non-null object 35 Zhuiping_content 2756 non-null object 36 Zhuiping_time 2756 non-null object 37 IMG_url_6 882 non-null object 38 Video_mainpic_9 473 non-null object 39 Video_url_9 473 non-null object 40 IMG_url_7 574 non-null object 41 IMG_url_8 279 non-null object 42 level_0 1681 non-null float64 43 index 20245 non-null float64 dtypes: float64(4), int64(1), object(39) memory usage: 10.9+ MB提取数据
1
2data = data.loc[:, data.columns[1:-2]]
data.info()Results:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 32419 entries, 0 to 32418 Data columns (total 41 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 29885 non-null float64 1 guid 32419 non-null object 2 nickname 32419 non-null object 3 content 32419 non-null object 4 creationTime 32419 non-null object 5 score 32419 non-null float64 6 productColor 30207 non-null object 7 referenceName 32419 non-null object 8 Video_mainpic_0 500 non-null object 9 Video_url_0 500 non-null object 10 Video_mainpic_1 492 non-null object 11 Video_url_1 492 non-null object 12 Video_mainpic_2 509 non-null object 13 Video_url_2 509 non-null object 14 Video_mainpic_3 476 non-null object 15 Video_url_3 476 non-null object 16 IMG_url_0 18849 non-null object 17 IMG_url_1 14269 non-null object 18 Video_mainpic_4 460 non-null object 19 Video_url_4 460 non-null object 20 Video_mainpic_5 500 non-null object 21 Video_url_5 500 non-null object 22 Video_mainpic_6 469 non-null object 23 Video_url_6 469 non-null object 24 IMG_url_2 9757 non-null object 25 Video_mainpic_7 533 non-null object 26 Video_url_7 533 non-null object 27 IMG_url_3 7876 non-null object 28 IMG_url_4 3474 non-null object 29 IMG_url_5 1780 non-null object 30 Video_mainpic_8 503 non-null object 31 Video_url_8 503 non-null object 32 Reply_0_content 739 non-null object 33 Reply_0_time 739 non-null object 34 Zhuiping_content 2756 non-null object 35 Zhuiping_time 2756 non-null object 36 IMG_url_6 882 non-null object 37 Video_mainpic_9 473 non-null object 38 Video_url_9 473 non-null object 39 IMG_url_7 574 non-null object 40 IMG_url_8 279 non-null object dtypes: float64(2), object(39) memory usage: 10.1+ MBSelect data
我们选取评论相关的数据作为此次处理对象。
1
2comments = data_copy.iloc[:, 1:7]
comments.head(2)Results:
id
guid
nickname
content
creationTime
score
0
1.582772e+10
d495506f3df9fa9fe5af352c8ecbea3f
****w
京东自营618屯货。图方便快捷,一直在京东自营购买牛肉。这次回购的牛腱子,是用来做干切牛肉。...
2021-06-18 15:30:41
5.0
1
1.582486e+10
39964bbdefbf80e9b48fd004531f5665
小***3
感谢感谢京东商城提供这么好的美食产品,好吃不贵经济实惠
2021-06-18 05:53:15
5.0
4.2 Word frequency analysis
4.2.1 Word frequency
Count word frequency
将所有评论作为一个文档进行词频统计。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19comments['content'].to_csv('./Process/content.txt', encoding = 'gbk', index = False)
stop_words = [i.strip() for i in open('中文停用词表.txt', 'r', encoding='utf8').readlines()]
stop_words.extend(['\n', '\xa0', '\u3000', '\u2002', ' ',])
# stop_words.extend(['用户未填写评价内容'])
jb.load_userdict('./Process/jieba_dict.txt')
jb.add_word('牛腱子', True)
with open('./Process/content.txt','r') as fr:
word = jb.cut(fr.read())
terms = pd.DataFrame(columns = ['Terms', 'Frequence'])
terms['Terms'] = list(data.keys())[1:]
terms['Frequence'] = list(data.values())[1:]
terms = terms.sort_values(by = 'Frequence', ascending = False)
terms['Label'] = terms['Terms'].apply(lambda x: 1 if x in stop_words else 0)
mod_terms = terms.loc[terms['Label'] == 0, ['Terms', 'Frequence']]
mod_terms.reset_index(drop = True).head(10)Results:
Terms
Frequence
0
牛肉
15919
1
买
15027
2
吃
11294
3
京东
11012
4
不错
10360
5
肉
6466
6
好吃
6250
7
购买
5738
8
牛腱
4933
9
做
4733
将词频分析结果存储
1
mod_terms.to_csv('./Process/analsis_content.csv', encoding = 'ansi', index = False)
Note: 得到词频结果后,我们对一些关键词进行了指标值的分类,具体分类情况见下一章节
4.2.2 Word cloud
1 | from wordcloud import WordCloud |
Results:

4.3 Feature engineering
对每个评论进行分词
1
2
3
4
5
6
7
8
9
10import jieba as jb
stop_words = [i.strip() for i in open('中文停用词表.txt', 'r', encoding='utf8').readlines()]
stop_words.extend(['\n', '\xa0', '\u3000', '\u2002', '',])
# stop_words.extend(['用户未填写评价内容'])
def get_str(x):
return ' '.join([str(i) for i in jb.cut(x, cut_all = False) if i not in stop_words])
comments['content_seg'] = comments['content'].apply(get_str)查看分词的结果
1
comments['content_seg'][:5]
Results:
0 京东 自营 618 屯货 图 方便快捷 京东 自营 购买 牛肉 回购 牛腱子 做 干切 牛肉... 1 感谢 感谢 京东 商城 提供 美食 产品 好吃 贵 经济 实惠 2 高压锅 不炖 太烂 吃 牛肉 感觉 慢慢 炖煮 味道 煮 机会 买 尝尝 煮 方法 不好 感觉 3 减肥 吃点 牛肉 买 两份 够吃 几天 4 物超所值 商品 设计 完美 外观 高大 爱不释手 客服 更是 热情 没话说 购物 满意 哈哈... Name: content_seg, dtype: object加载指标分类结果
1
2
3
4
5
6
7pd_maps = pd.read_excel('./Process/Analysis_content.xlsx', sheet_name = 'Sheet2')
key_words = pd_maps['Terms']
labels = pd_maps['Label']
maps = dict(zip(key_words, labels))
pd_maps.sample(5)Results:
Terms
Label
35
牌子
品牌
74
差评
印象
25
味道
口味
33
品牌
品牌
49
筋
肉类
计算每个关键词在该条评论中的频次
1
2
3
4
5frequence = [comments['content_seg'].apply(lambda x: x.count(i)) for i in key_words]
for i in range(len(key_words)):
comments[key_words[i]] = frequence[i]
comments.head(3)Results:
id
guid
nickname
content
creationTime
score
content_seg
包装
活动
优惠
...
感觉
放心
推荐
还会
好评
信赖
失望
体验
五星
差评
0
1.582772e+10
d495506f3df9fa9fe5af352c8ecbea3f
****w
京东自营618屯货。图方便快捷,一直在京东自营购买牛肉。这次回购的牛腱子,是用来做干切牛肉。...
2021-06-18 15:30:41
5.0
京东 自营 618 屯货 图 方便快捷 京东 自营 购买 牛肉 回购 牛腱子 做 干切 牛肉...
0
0
0
...
0
0
0
0
0
0
0
0
0
0
1
1.582486e+10
39964bbdefbf80e9b48fd004531f5665
小***3
感谢感谢京东商城提供这么好的美食产品,好吃不贵经济实惠
2021-06-18 05:53:15
5.0
感谢 感谢 京东 商城 提供 美食 产品 好吃 贵 经济 实惠
0
0
0
...
0
0
0
0
0
0
0
0
0
0
2
1.582004e+10
7d3fe9e265681e75361982339900af6e
常****
不可使用高压锅,要不炖的太烂了,都没有吃牛肉的感觉了。还是需要慢慢炖煮,把味道煮进去最好,有...
2021-06-17 10:48:28
4.0
高压锅 不炖 太烂 吃 牛肉 感觉 慢慢 炖煮 味道 煮 机会 买 尝尝 煮 方法 不好 感觉
0
0
0
...
2
0
0
0
0
0
0
0
0
0
3 rows × 82 columns
可以发现增加了75列,这75列表示该列名称所示的关键词在评论中出现的频次。
关键词的指标
对上述的关键词进行指标分类和频次加总,映射关系见 pd_maps。
1
2
3
4
5
6label_unq = list(labels.unique())
for lab in label_unq:
terms = pd_maps.groupby('Label').get_group(lab)['Terms'].agg(lambda x: list(x.to_list()))
comments['Top-'+lab] = comments.loc[:, terms].sum(1)
comments.head(3)Results:
id
guid
nickname
content
creationTime
score
content_seg
包装
活动
优惠
...
Top-口感
Top-口味
Top-派送
Top-品牌
Top-品质
Top-渠道
Top-肉类
Top-肉质
Top-物流
Top-印象
0
1.582772e+10
d495506f3df9fa9fe5af352c8ecbea3f
****w
京东自营618屯货。图方便快捷,一直在京东自营购买牛肉。这次回购的牛腱子,是用来做干切牛肉。...
2021-06-18 15:30:41
5.0
京东 自营 618 屯货 图 方便快捷 京东 自营 购买 牛肉 回购 牛腱子 做 干切 牛肉...
0
0
0
...
0
2
0
0
1
4
4
3
0
0
1
1.582486e+10
39964bbdefbf80e9b48fd004531f5665
小***3
感谢感谢京东商城提供这么好的美食产品,好吃不贵经济实惠
2021-06-18 05:53:15
5.0
感谢 感谢 京东 商城 提供 美食 产品 好吃 贵 经济 实惠
0
0
0
...
0
2
0
0
0
2
0
0
0
0
2
1.582004e+10
7d3fe9e265681e75361982339900af6e
常****
不可使用高压锅,要不炖的太烂了,都没有吃牛肉的感觉了。还是需要慢慢炖煮,把味道煮进去最好,有...
2021-06-17 10:48:28
4.0
高压锅 不炖 太烂 吃 牛肉 感觉 慢慢 炖煮 味道 煮 机会 买 尝尝 煮 方法 不好 感觉
0
0
0
...
0
2
0
0
0
0
1
1
0
2
3 rows × 96 columns
增加了14列一级指标。
生成标签
将 score 小于三的划分为负面评论
0,大于三的划分为正面评论1。1
comments['Label'] = comments['score'].apply(lambda x: 1 if x >=3 else 0)
4.4 TF-IDF
TP-IDF 处理
将评论文本数据转化为 10 维的向量数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
from sklearn.metrics import accuracy_score as ac
from sklearn.model_selection import train_test_split
from sklearn.decomposition import TruncatedSVD
from sklearn.feature_extraction.text import TfidfVectorizer
%matplotlib inline
def get_tfidf(df, names):
tfidf_enc_tmp = TfidfVectorizer(ngram_range=(1, 2))
tfidf_vec_tmp = tfidf_enc_tmp.fit_transform(df[names])
svd_tag_tmp = TruncatedSVD(n_components=10, n_iter=20, random_state=2019)
tag_svd_tmp = svd_tag_tmp.fit_transform(tfidf_vec_tmp)
tag_svd_tmp = pd.DataFrame(tag_svd_tmp)
tag_svd_tmp.columns = [f'{names}_svd_{i}' for i in range(10)]
return tag_svd_tmp
#return pd.concat([df[[merge_id]], tag_svd_tmp], axis=1)
detail_svd = get_tfidf(comments, 'content_seg')
comments = pd.concat([comments, detail_svd], axis = 1)
comments.columnsResults:
1
2
3
4
5
6
7
8Index(['id', 'guid', 'nickname', 'content', 'creationTime', 'score',
'content_seg', '包装', '活动', '优惠',
...
'content_seg_svd_0', 'content_seg_svd_1', 'content_seg_svd_2',
'content_seg_svd_3', 'content_seg_svd_4', 'content_seg_svd_5',
'content_seg_svd_6', 'content_seg_svd_7', 'content_seg_svd_8',
'content_seg_svd_9'],
dtype='object', length=107)至此,特征工程处理完毕。
4.5 LightGBM 建模分析
LightGBM 建模分析
模型定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54def sub_on_line(train_, test_, pred, label, is_shuffle=True):
n_splits = 5
folds = KFold(n_splits=n_splits, shuffle=is_shuffle, random_state=1024)
sub_preds = np.zeros((test_.shape[0], folds.n_splits))
train_.loc[:, f'{label}_pred'] = 0
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = pred
print(f'Use {len(pred)} features ...')
auc_scores = []
params = {
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': 63,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'seed': 1,
'bagging_seed': 1,
'feature_fraction_seed': 7,
'min_data_in_leaf': 20,
'nthread': -1,
'verbose': -1
}
for n_fold, (train_idx, valid_idx) in enumerate(folds.split(train_.index), start=1):
print(f'the {n_fold} training start ...')
train_x, train_y = train_.loc[train_idx, pred], train_.loc[train_idx, label]
valid_x, valid_y = train_.loc[valid_idx, pred], train_.loc[valid_idx, label]
print(f'for train user:{len(train_idx)}\nfor valid user:{len(valid_idx)}')
dtrain = lgb.Dataset(train_x, label=train_y)
dvalid = lgb.Dataset(valid_x, label=valid_y)
clf = lgb.train(
params=params,
train_set=dtrain,
num_boost_round=10000,
valid_sets=[dvalid],
early_stopping_rounds=500,
verbose_eval=100
)
sub_preds[:, n_fold - 1] = clf.predict(test_[pred], num_iteration=clf.best_iteration)
fold_importance_df[f'fold_{n_fold}_imp'] = clf.feature_importance()
auc_scores.append(clf.best_score['valid_0']['auc'])
train_.loc[valid_idx, f'{label}_pred'] = clf.predict(valid_x, num_iteration=clf.best_iteration)
five_folds = [f'fold_{f}_imp' for f in range(1, n_splits + 1)]
fold_importance_df['avg_imp'] = fold_importance_df[five_folds].mean(axis=1)
fold_importance_df.sort_values(by='avg_imp', ascending=False, inplace=True)
fold_importance_df[['Feature', 'avg_imp']].to_csv('./Process/feat_imp_base.csv', index=False, encoding='ansi')
test_[f'{label}_pred'] = np.mean(sub_preds, axis=1).round()
# print(classification_report(test_[f'{label}_pred'], test_[label], digits=4))
print('auc score', np.mean(auc_scores))
return test_建模分析
1
2
3
4
5
6
7
8import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import classification_report
label = 'Label'
train = train.reset_index(drop = True)
test = test.reset_index(drop = True)
test_pred = sub_on_line(train, test, features, label)Results:
Use 99 features ... the 1 training start ... for train user:20748 for valid user:5187 Training until validation scores don't improve for 500 rounds [100] valid_0's auc: 0.912947 [200] valid_0's auc: 0.923455 [300] valid_0's auc: 0.932511 [400] valid_0's auc: 0.938316 [500] valid_0's auc: 0.9423 [600] valid_0's auc: 0.945808 [700] valid_0's auc: 0.948631 [800] valid_0's auc: 0.950704 [900] valid_0's auc: 0.952399 [1000] valid_0's auc: 0.953738 [1100] valid_0's auc: 0.95514 [1200] valid_0's auc: 0.955977 [1300] valid_0's auc: 0.956791 [1400] valid_0's auc: 0.957412 [1500] valid_0's auc: 0.957956 [1600] valid_0's auc: 0.958558 [1700] valid_0's auc: 0.958972 [1800] valid_0's auc: 0.959205 [1900] valid_0's auc: 0.959827 [2000] valid_0's auc: 0.960179 [2100] valid_0's auc: 0.96054 [2200] valid_0's auc: 0.960713 [2300] valid_0's auc: 0.960969 [2400] valid_0's auc: 0.961075 [2500] valid_0's auc: 0.961292 [2600] valid_0's auc: 0.961535 [2700] valid_0's auc: 0.961669 [2800] valid_0's auc: 0.961738 [2900] valid_0's auc: 0.962018 [3000] valid_0's auc: 0.962061 [3100] valid_0's auc: 0.962088 [3200] valid_0's auc: 0.96215 [3300] valid_0's auc: 0.962239 [3400] valid_0's auc: 0.962313 [3500] valid_0's auc: 0.9623 [3600] valid_0's auc: 0.962196 [3700] valid_0's auc: 0.962222 [3800] valid_0's auc: 0.962309 [3900] valid_0's auc: 0.962354 [4000] valid_0's auc: 0.962443 [4100] valid_0's auc: 0.96247 [4200] valid_0's auc: 0.962388 [4300] valid_0's auc: 0.962324 [4400] valid_0's auc: 0.962444 [4500] valid_0's auc: 0.962368 Early stopping, best iteration is: [4067] valid_0's auc: 0.962502 Early stopping, best iteration is: [5067] valid_0's auc: 0.955291 ... auc score 0.9550347381665819分类结果
1
print(classification_report(test_pred[f'{label}_pred'], test_pred[label], digits=4))
precision recall f1-score support 0.0 0.7155 0.8783 0.7886 567 1.0 0.9881 0.9665 0.9772 5917 accuracy 0.9588 6484 macro avg 0.8518 0.9224 0.8829 6484 weighted avg 0.9642 0.9588 0.9607 6484可以发现分类结果还算不错。
5. Conclusion
至此,京东评论爬取和情感分析处理完毕。由于是个人的比赛项目,本文不提供更详细的数据,代码和部分结果已基本附上。所获取的数据仅用于比赛。图片皆为个人爬取后的数据截图,如有侵权,可联系邮箱进行删除。
申明:本文仅供学习和交流,请珍惜作者劳动成果,勿用作商业用途,如需商业用途或业务交流可联系邮箱
e-mail:yangsuoly@qq.com 进行进一步交流。