1. Study goals
- 学习词向量的概念
- 用 Skip-thought 模型训练词向量
- 学习使用 PyTorch dataset和 dataloader
- 学习定义 PyTorch 模型
- 学习 torch.nn 中常见的 Module
- Embedding
- 学习常见的 PyTorch operations
- bmm
- logsigmoid
- 保存和读取 PyTorch 模型
2. Word vector
在计算机中如何表示一个词:

可以使用一些上位词或同义词来形容某个词。但这样表示存在如下问题:
- 不能分辨细节的差别
- 需要大量人为劳动
- 主观
- 无法发现新词
- 难以精确计算词之间的相似度
2.1 Discrete representation
2.1.1 One-hot
使用 One-hot 来离散表示词向量。
语料库 (Corpus):
John likes to watch movies. Mary likes too.
John also likes to watch football games.词典 (Dictionary)
1
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10}
One-hot representation
John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] too: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
One-hot 表示的特点:
- 词典包含 10 个单词,每个单词有唯一索引
- 在词典中的顺序和在句子中的顺序没有关联
2.2.2 Bag of Words
文档的向量表示可以直接将各词的词向量表示加和。如:
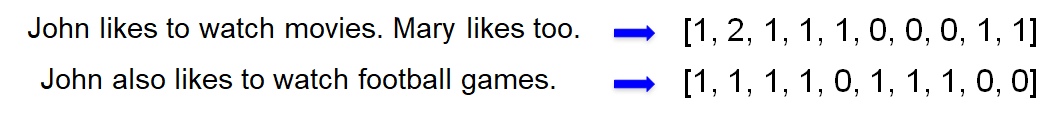
词权重表示(词在文档中的顺序没有被考虑):
TF-IDF(Term Frequency - Inverse Document Frequency)
Specifically, TF-IDF is defines as: {\rm{tf}\text{-}\rm{idf}}(t, d, D) = f _{t,d}
\cdot \log \frac{N}{n_t}
where f_{t, d} is the raw frequency of term t in document d, N is the total number of documents in the corpus, and n_t is the total number of documents containing at least one occurrence of term t.
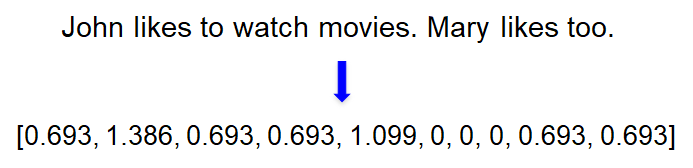
- Binary weighting

2.2.3 Bi-gram and N-gram
为 2-gram 建立索引:
1 | "John likes": 1, |
所以可以得到如下表示:

而 N-gram 模型参数与 N 之间的关系:
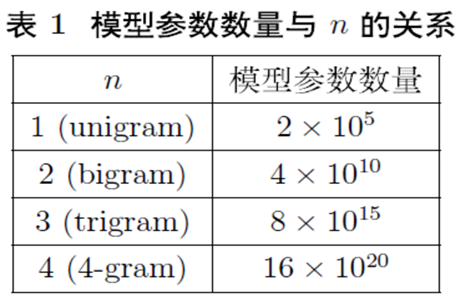
N-gram 的优缺点:
- 优点:考虑了词的顺序
- 缺点:词表的膨胀
2.3 Distributed representation
2.3.1 Preface
从上一小节可以发现离散表示存在如下问题:
无法衡量词向量之间的关系
太稀疏,难以捕捉文本的含义。各种度量(与或非、距离)都不合适.

- 词表维度随着语料库增长膨胀
N-gram词序列随着语料库膨胀更快- 数据稀疏性问题
为了弥补这些不足,对词编码表示提出如下要求:
词编码需要保证词的相似性。

向量空间分布的相似性
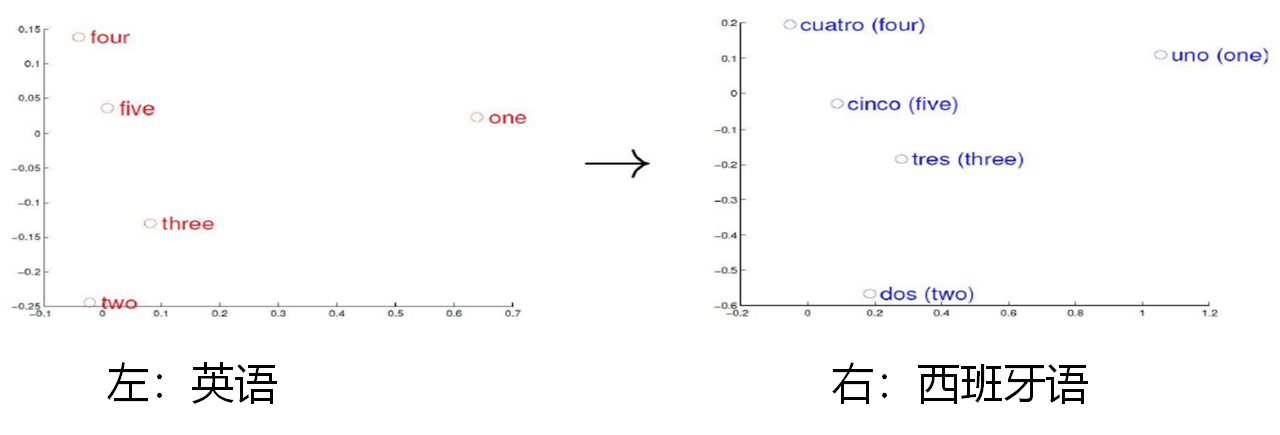
向量空间子结构
\begin{align} V_{King} - V_{Queen} + V_{Women} &= V_{Man} \\ V_{Paris} - V_{France} + V_{German} &= V_{Berlin} \end{align}
最终目标:词向量表示作为机器学习、特别是深度学习的输入和表示空间。
因此,有学者考虑使用分布式表示来生成词向量。分布式表示即用一个词附近的其他词来表示该词。这也是现代统计自然语言处理中最有创意的想法之一。
如, banking 附近的词将会代表 banking
的含义。

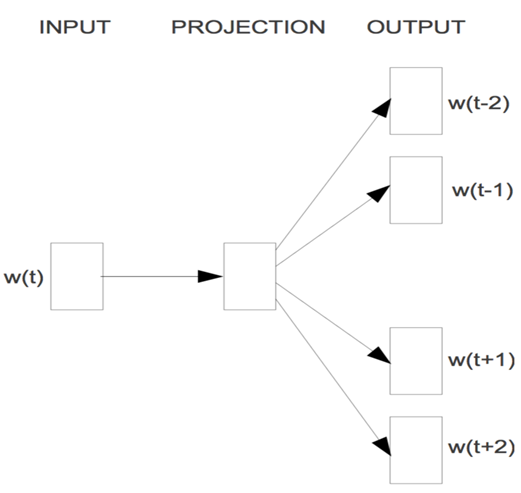
2.3.2 Word2Vec: Skip-Gram model
该模型具有以下特点:
- 无隐层
- 投影层也可省略
- 每个词向量作为log-linear模型的输入
目标函数 (Objective function):
\frac{1}{T} \sum^{T}_{t=1} \sum_{-c \leq j \leq c,\ j \neq 0} \log (p(w_{t+j} | w_t ))
概率密度 (Probability density)
概率密度由
Softmax给出:p(o|c) = \frac{\exp \left(u^T_o v_c \right)}{\sum^W_{w=1} \exp \left(u^T_w v_c \right)}
o 表示
output, c 表示center word即输入。该训练模型存在一个问题:分母有一个summation操作,表示需要用中心词对语料库中所有词做一个点积,这会导致需要非常大的内容,训练过程会很慢。损失函数 (Loss function)
\begin{aligned} \min J &= -\log P\left(w_{c-m}, \ldots, w_{c-1}, w_{c+1}, \ldots, w_{c+m} \mid w_{c}\right) \\ &=-\log \prod_{j=0, j \neq m}^{2 m} P\left(w_{c-m+j} \mid w_{c}\right) \\ &=-\log \prod_{j=0, j \neq m}^{2 m} P\left(u_{c-m+j} \mid v_{c}\right) \\ &=-\log \prod_{j=0, j \neq m}^{2 m} \frac{\exp \left(u_{c-m+j}^{T} v_{c}\right)}{\sum_{k=1}^{|V|} \exp \left(u_{k}^{T} v_{c}\right)} \\ &=-\sum_{j=0, j \neq m}^{2 m} u_{c-m+j}^{T} v_{c}+2 m \log \sum_{k=1}^{|V|} \exp \left(u_{k}^{T} v_{c}\right) \end{aligned}
负采样 (Negative sampling)
P(w|\text{context}(w)):一个正样本,V-1 个负样本,对负样本做采样。
\begin{align} P(D=1 \mid w, c, \theta) &= \frac{1}{1+e^{\left(-v_{c}^{T} v_{w}\right)}} \\ \log \sigma\left(u_{c-m+j}^{T} \cdot v_{c}\right) &+ \sum_{k=1}^{K} \log \sigma\left(-\tilde{u}_{k}^{T} \cdot v_{c}\right) \end{align}
where, \{ \tilde{u}_k | k = 1 \dots K \} is obtained by negative sampling.
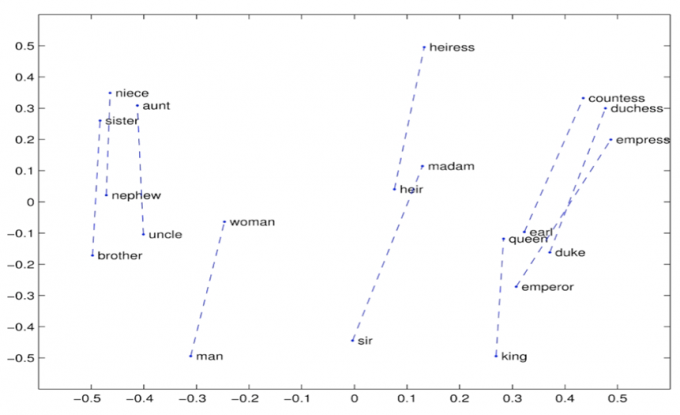
2.3.3 Word embendding visualization
词向:公司 —— CEO
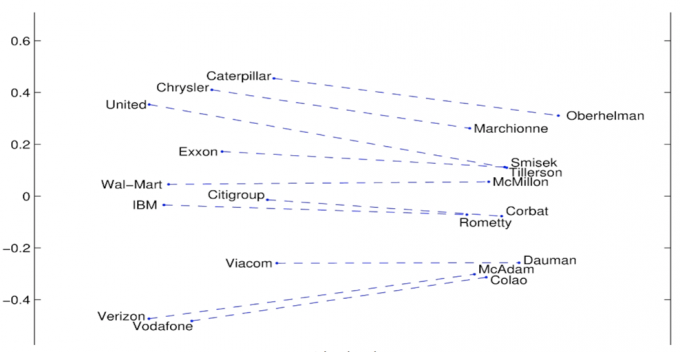
\begin{align*} \text{Fig. 公司} \leftrightarrow \rm{CEO} \end{align*}
词向:比较级和最高级
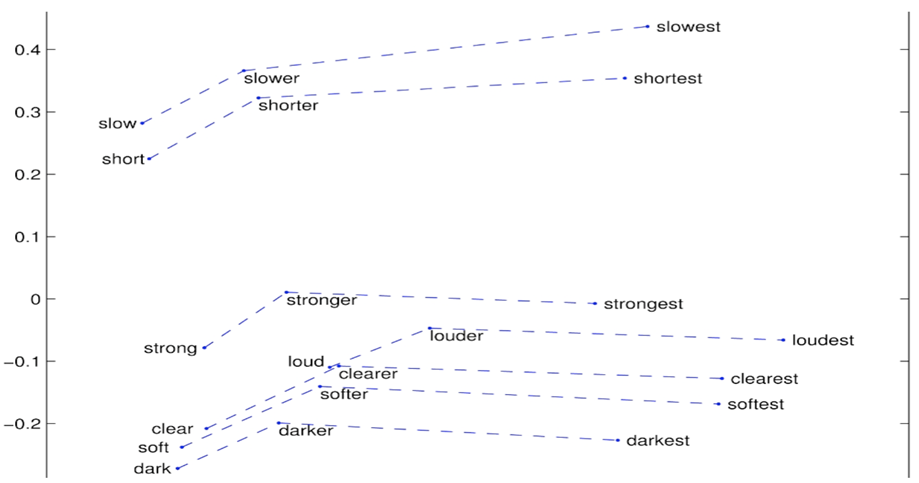
Fig. 比较级和最高级
评估效果:词类比任务
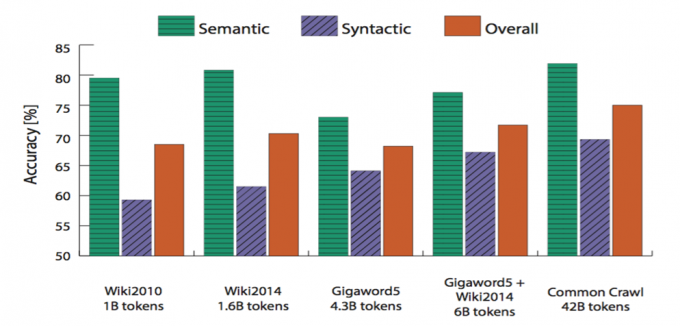
Fig. Accuracy on the analogy task for 300-D vectors trained on different corpora
19544个类比问题:
- Athens is to Greece as Berlin is to __?
- Bigger is to Big as Greater is to __?
效果评估:词相似度任务
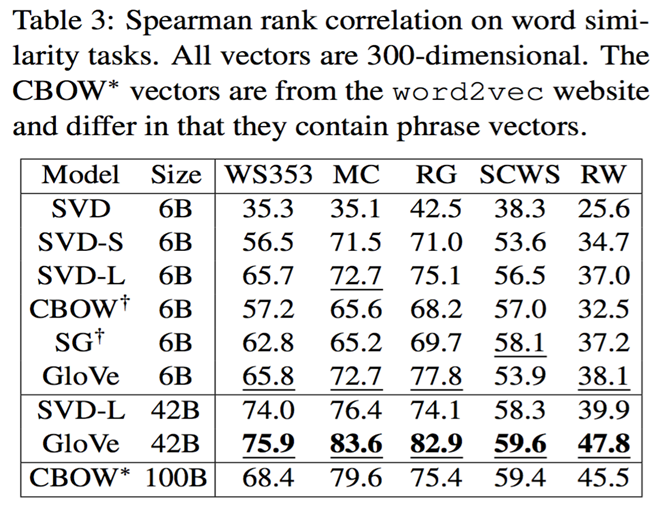
其中,
SVD模型只保留出现次数最大的 1 万个词,记为 X_{trunc},SVD-S为 \sqrt{X_{trunc}},SVD-L为 \log (1+X_{trunc})。效果评估:作为特征用于
CRF实体识别NER任务包含 437, 905 个离散特征,额外的 50 维连续特征。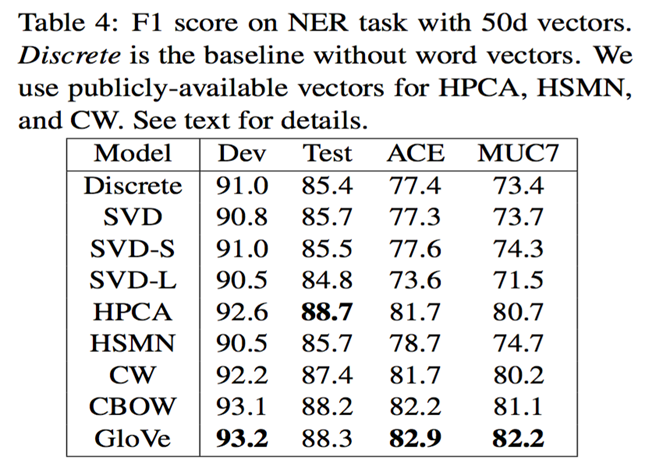
3. Implement Word2Vec with pytorch
3.1 简介
该文档中使用的训练数据可从如下方式下载:Click Here。
在本节的代码中,尽可能尝试复现论文 Distributed
Representations of Words and Phrases and their Compositionality
中训练词向量的方法. 我们会实现 Skip-gram
模型,并且使用论文中 noice contrastive sampling
的目标函数。
这篇论文有很多模型实现的细节,这些细节对于词向量的好坏至关重要。虽然无法完全复现论文中的实验结果,主要是由于计算资源等各种细节原因,但是我们还是可以大致展示如何训练词向量。
以下是没有实现的细节:
- subsampling:参考论文section 2.3
本章节的代码主要借助 Google colab 平台进行实现。
3.2 Implementation
3.2.1 Platform and enviroment setting
Mount google driver
借助
Google driver可以上传个人文件以及保存notebook。1
2from google.colab import drive
drive.mount('/content/drive')Results:
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).GPU Setting and information
由于训练量较大,使用
GPU进行训练词嵌入模型,Colab可以免费使用GPU和TPU。操作方式:\rm{Edit \rightarrow Notebook settings \rightarrow Hardware accelerator \rightarrow GPU \rightarrow Save}。查看装在的
GPU信息。1
!nvidia-smi
Results:
Wed Aug 4 09:29:20 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.42.01 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 | | N/A 35C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
3.2.2 Load modules and procession
Load modules
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as tud
from collections import Counter
import numpy as np
import pandas as pd
import random
import math
import scipy
import sklearn
from sklearn.metrics.pairwise import cosine_similarity
USE_CUDA = torch.cuda.is_available()
random.seed(1)
np.random.seed(1)
torch.manual_seed(1)
if USE_CUDA:
torch.cuda.manual_seed(1)
# Seting hyper parameters
K = 100 # number of negative samples
C = 3 # context window
NUM_EPOCHS = 2 # The number of epochs of training
MAX_VOCAB_SIZE = 30000 # the vocabulary size
BATCH_SIZE = 128 # the batch size
LEARNING_RATE = 0.2 # the initial learning rate
EMBEDDING_SIZE = 100
LOG_FILE = "word-embedding.log"
def word_tokenize(text):
return text.split()Load data and count data
- 从文本文件中读取所有的文字,通过这些文本创建一个
vocabulary - 由于单词数量可能太大,我们只选取最常见的
MAX_VOCAB_SIZE个单词 - 我们添加一个
UNK单词表示所有不常见的单词 - 我们需要记录单词到
index的mapping,以及index到单词的mapping,单词的count,单词的(normalized) frequency,以及单词总数。
加载数据和计算词频:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15with open('/content/drive/MyDrive/Word_embedding/text8.train.txt', 'r') as fin:
text = fin.read()
text = text.split()
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE - 1))
vocab['<unk>'] = len(text) - np.sum(list(vocab.values()))
idx_to_word = [word for word in vocab.keys()]
word_to_idx = {word:i for i, word in enumerate(idx_to_word)}
word_counts = np.array([count for count in vocab.values()], dtype = np.float32)
word_freqs = word_counts / np.sum(word_counts)
word_freqs = word_freqs ** (3./4.)
word_freqs = word_counts / np.sum(word_counts) # 用来做 negative sampling
VOCAB_SIZE = len(idx_to_word)Notes: 本人将项目文件存储在谷歌云盘的
/content/drive/MyDrive/Word_embedding/目录下,如想复现改代码,应将该项目文件夹改为个人文件夹目录,下同。- 从文本文件中读取所有的文字,通过这些文本创建一个
Create Dateset and Dataloader
一个
dataloader需要以下内容:- 把所有text编码成数字,然后用
subsampling预处理这些文字。 - 保存 vocabulary,单词 count,normalized word frequency
- 每个 iteration sample 一个中心词
- 根据当前的中心词返回
context单词 - 根据中心词 sample 一些 negative 单词
- 返回单词的 counts
有了 dataloader 之后,我们可以轻松随机打乱整个数据集,拿到一个 batch 的数据等等。这里有一个好的 tutorial 介绍如何使用 PyTorch dataloader. 为了使用 dataloader,我们需要定义以下两个 function:
__len__\rm Function 需要返回整个数据集中有多少个item__get__根据给定的index返回一个item
先创建
Dataset类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class WordEmbeddingDataset(tud.Dataset):
def __init__(self, text, word_to_idx, idx_to_word, word_freqs, word_counts):
''' text: a list of words, all text from the training dataset
word_to_idx: the dictionary from word to idx
idx_to_word: idx to word mapping
word_freq: the frequency of each word
word_counts: the word counts '''
super(WordEmbeddingDataset, self).__init__()
self.text_encoded = [word_to_idx.get(t, VOCAB_SIZE-1) for t in text]
self.text_encoded = torch.Tensor(self.text_encoded).long()
self.word_to_idx = word_to_idx
self.idx_to_word = idx_to_word
self.word_freqs = torch.Tensor(word_freqs)
self.word_counts = torch.Tensor(word_counts)
def __len__(self):
''' 返回整个数据集(所有单词)的长度 '''
return len(self.text_encoded)
def __getitem__(self, idx):
''' 这个function返回以下数据用于训练
- 中心词
- 这个单词附近的(positive)单词
- 随机采样的K个单词作为negative sample
'''
center_word = self.text_encoded[idx]
pos_indices = list(range(idx-C, idx)) + list(range(idx+1, idx+C+1)) # window 内单词的 index
pos_indices = [i%len(self.text_encoded) for i in pos_indices] # 取余,防止超出 text 长度,将文本闭环 -1%10 = 9
pos_words = self.text_encoded[pos_indices] # 周围单词
neg_words = torch.multinomial(self.word_freqs, K * pos_words.shape[0], True) # 负采样单词
return center_word, pos_words, neg_words创建
Dataset和Dataloader:1
2dataset = WordEmbeddingDataset(text, word_to_idx, idx_to_word, word_freqs, word_counts)
dataloader = tud.DataLoader(dataset, batch_size = BATCH_SIZE, shuffle = True, num_workers = 2)为了更好理解
Dataloader中返回的内容,查看其信息:1
2
3
4
5for e in range(NUM_EPOCHS):
for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):
print(input_labels, pos_labels, neg_labels)
if i > 0:
breakResults:
tensor([ 1769, 62, 11, 21115, 6716, 29999, 1045, 138, 460, 29999, 29999, 29999, 1, 18, 9235, 2, 8312, 9, 13824, 29999, 29999, 1714, 22, 1562, 0, 30, 0, 0, 22, 990, 445, 33, 4390, 7219, 0, 255, 1217, 5, 1, 4, 29, 20, 0, 2487, 1534, 991, 3, 18, 28, 141, 193, 2800, 1, 9, 337, 127, 157, 149, 107, 236, 6, 84, 43, 29828, 52, 403, 186, 83, 1265, 552, 2, 595, 2798, 33, 12, 8462, 10, 127, 8872, 1514, 6620, 217, 1, 3680, 5804, 5, 29999, 956, 19058, 21389, 495, 39, 30, 349, 416, 11, 5, 1, 1, 6, 1, 122, 211, 2719, 873, 0, 22, 24620, 22, 93, 0, 535, 99, 1734, 3, 1269, 5909, 3, 15, 5069, 1706, 17024, 29999, 28, 169, 129, 5025, 10759]) tensor([[27921, 1, 107, 3219, 40, 5], [ 3832, 634, 1536, 116, 2567, 938], [ 661, 296, 620, 227, 774, 4676], [ 98, 8425, 29, 34, 1069, 60], [ 22, 253, 66, 16886, 38, 49], [29999, 604, 29999, 4965, 3, 8], [ 2274, 1081, 10, 4, 0, 2128], [ 11, 30, 616, 29999, 17, 52], [ 15, 7, 22, 10132, 6, 14444], [ 51, 29999, 2, 32, 194, 10], [13251, 0, 540, 17, 37, 29392], [ 86, 11, 26305, 4, 0, 42], [ 6604, 0, 553, 0, 6818, 387], [ 496, 246, 331, 482, 312, 0], [28413, 451, 400, 1494, 1861, 1], [ 245, 143, 29999, 29999, 7, 4501], [ 6623, 26, 68, 75, 3511, 76], [ 9, 15, 3, 7, 7, 15], [ 1812, 1, 3571, 9824, 0, 258], [ 1535, 811, 877, 1535, 811, 877], [ 3, 20, 9, 26166, 537, 16], [ 1326, 168, 639, 29999, 325, 11916], [ 3, 8, 15, 26, 17, 108], [10360, 2, 940, 60, 5, 182], [ 2, 2319, 24, 4398, 1, 458], [ 0, 3476, 38, 139, 1114, 3434], [ 5, 26413, 143, 1797, 17, 45], [ 617, 46, 736, 14267, 55, 3435], [ 3, 8, 3, 29999, 12448, 7130], [ 22, 15, 29999, 17, 0, 45], [ 142, 0, 9504, 10, 205, 1181], [ 2, 1305, 28342, 1968, 5, 979], [ 420, 711, 2959, 1, 29999, 4], [ 3, 16, 12, 47, 527, 0], [ 11, 470, 1, 29999, 2, 780], [ 31, 4261, 23, 96, 108, 1], [ 199, 238, 100, 13330, 1, 1259], [ 232, 6, 31, 851, 1244, 1210], [ 1, 2191, 2570, 112, 1, 2191], [ 2, 731, 5379, 3, 8, 3], [ 0, 125, 6752, 686, 18, 5659], [ 9, 7, 7, 0, 17323, 40], [ 1, 158, 1, 674, 2110, 302], [ 1625, 2125, 2, 374, 28455, 4], [ 19, 0, 66, 5072, 3224, 5683], [11916, 991, 29999, 6102, 634, 524], [13946, 277, 118, 8, 8, 12], [ 0, 246, 365, 18480, 13442, 4], [ 619, 598, 8108, 227, 8108, 26], [ 1978, 18, 183, 2042, 3594, 511], [ 90, 1265, 1901, 1, 50, 63], [ 8943, 12354, 0, 1355, 2, 89], [ 17, 5, 928, 8299, 1, 3773], [ 3, 12, 3, 3180, 12330, 29999], [ 389, 0, 246, 2, 1090, 4], [ 29, 3445, 27, 3698, 185, 29], [11829, 28, 10866, 2075, 3, 20], [ 7794, 1, 0, 12126, 1, 0], [ 18, 4313, 19, 767, 72, 70], [ 932, 1981, 4, 788, 4574, 3862], [ 37, 31, 16090, 11, 0, 29999], [ 2, 114, 0, 80, 773, 1456], [ 804, 12614, 2, 2046, 4, 187], [ 1705, 1218, 18, 35, 17, 1369], [ 838, 609, 0, 7808, 4002, 10387], [ 2060, 47, 13230, 0, 29999, 2], [ 27, 23856, 25, 3948, 23, 0], [ 6476, 6, 52, 26, 10, 696], [ 7862, 13, 0, 435, 41, 26], [ 53, 56, 9364, 582, 0, 1797], [ 2546, 23, 65, 42, 29999, 4262], [ 465, 82, 4, 2, 3584, 1], [ 2549, 1472, 2, 2005, 19, 33], [ 16, 7, 14, 1167, 34, 14015], [ 398, 274, 7, 20, 9, 16], [ 55, 288, 0, 1, 0, 376], [ 215, 6, 5502, 696, 6, 24355], [ 4479, 4, 0, 81, 1, 0], [ 5458, 6299, 23, 49, 14646, 29424], [ 1192, 6, 31, 17208, 4060, 1592], [ 1, 7227, 67, 2, 3004, 3581], [ 941, 1300, 23, 1918, 6600, 4329], [ 0, 413, 113, 6058, 26, 40], [ 0, 2736, 524, 5, 874, 23], [ 14, 159, 6298, 1967, 38, 265], [16474, 188, 14056, 122, 4866, 109], [ 1, 0, 29999, 29999, 5, 170], [ 1702, 2, 0, 3249, 10, 6748], [ 45, 2249, 15372, 2155, 987, 24], [ 738, 24, 0, 421, 3, 9], [ 2, 22746, 1041, 13, 21, 81], [ 0, 8999, 3115, 108, 64, 8659], [ 347, 18, 11663, 2067, 223, 3300], [14809, 18381, 2367, 23, 29999, 29999], [ 355, 5, 1485, 4, 44, 1213], [ 1699, 11, 110, 42, 17711, 105], [ 0, 4378, 34, 1818, 1, 0], [ 148, 300, 121, 325, 570, 225], [ 5, 171, 137, 5, 29999, 2936], [ 28, 603, 10573, 31, 59, 4], [ 0, 979, 28719, 1363, 4, 387], [ 3548, 5920, 13, 14810, 8828, 27], [ 2763, 26, 29999, 12, 20, 7], [ 143, 1, 0, 5336, 1628, 962], [ 7466, 50, 1, 39, 1705, 948], [ 0, 172, 10, 120, 1, 5], [ 4, 29, 3, 12, 15, 2973], [ 7, 7, 8, 9, 7, 7], [ 128, 9, 3, 128, 21, 128], [ 114, 32, 2546, 19, 0, 19029], [ 20, 2, 4, 937, 3, 8], [ 13, 44, 29999, 2, 40, 37], [ 3267, 6, 29999, 26, 1284, 235], [ 0, 26803, 2946, 32, 860, 4], [ 1278, 731, 2, 161, 3112, 211], [ 0, 1598, 2, 32, 298, 1991], [ 1, 16, 3998, 19, 25, 2796], [ 12, 9, 16, 12, 8, 20], [ 22, 3, 8, 3, 506, 3], [ 3402, 34, 4350, 6, 181, 97], [ 1, 468, 845, 1, 14700, 2], [ 1, 593, 2870, 12722, 10, 148], [ 742, 1811, 74, 2, 19377, 0], [ 256, 97, 3249, 6112, 7338, 213], [ 4258, 11709, 2797, 156, 3120, 29999], [ 8, 3, 20, 12, 8, 3], [ 261, 4, 1856, 321, 6, 5], [ 82, 5767, 2, 20954, 79, 5]]) tensor([[ 1, 12, 15, ..., 65, 7, 11553], [10142, 0, 81, ..., 28522, 147, 31], [ 5, 0, 29999, ..., 5896, 6, 29999], ..., [ 3780, 818, 58, ..., 0, 24, 178], [ 1756, 416, 23, ..., 398, 1444, 2], [ 1, 203, 8880, ..., 0, 16466, 3]]) tensor([ 114, 24821, 3643, 0, 1354, 198, 808, 1074, 268, 231, 223, 1095, 3, 2658, 484, 1, 10670, 208, 753, 4, 6583, 2, 29, 345, 802, 0, 7046, 23, 85, 101, 32, 49, 100, 8, 6, 5, 6, 6905, 12, 1525, 166, 28670, 953, 796, 147, 7, 200, 74, 3542, 21, 7, 2, 105, 22, 18, 3, 21, 880, 16, 18, 2510, 0, 32, 32, 6, 592, 27, 2351, 34, 30, 0, 74, 248, 7749, 3, 3, 90, 4, 12, 16497, 374, 29999, 96, 49, 6, 1, 6, 18399, 15, 26517, 0, 7, 92, 13, 7, 543, 349, 214, 318, 2925, 15, 3925, 255, 889, 57, 10978, 29999, 3, 445, 6, 1355, 14, 1061, 325, 6, 29999, 113, 3, 343, 16, 56, 1841, 29379, 16743, 5, 1302, 15, 4]) tensor([[ 5, 26934, 8395, 15733, 18, 6126], [18869, 348, 11, 3206, 4183, 673], [10297, 1, 32, 10, 0, 13983], [ 5245, 82, 23, 122, 76, 2], [ 11, 547, 6, 0, 4723, 11], [ 23, 0, 3048, 2, 0, 12032], [24168, 23, 29999, 3273, 6, 5672], [ 1399, 20662, 1048, 62, 26, 133], [ 29, 164, 1606, 29931, 2455, 4], [ 5865, 251, 0, 4031, 1, 2551], [ 22, 129, 947, 29999, 29999, 9], [ 131, 18, 0, 271, 13, 1700], [ 145, 1093, 2921, 8, 22, 16], [ 6, 1327, 599, 3433, 19, 4501], [29999, 8372, 34, 168, 12123, 204], [ 5, 379, 419, 9281, 6, 22491], [29999, 13761, 29999, 26259, 2, 29999], [ 1649, 41, 3, 93, 4492, 0], [17917, 40, 53, 26, 40, 297], [29999, 16765, 29999, 3, 8, 8], [ 19, 0, 258, 275, 31, 3670], [29999, 153, 1263, 438, 4615, 73], [ 3, 13732, 8965, 1661, 11719, 34], [ 705, 6, 30, 12289, 9, 398], [ 1687, 1, 5, 562, 2086, 5], [ 0, 2337, 60, 1566, 1, 20], [ 6824, 20608, 2, 3965, 6967, 0], [ 100, 76, 11, 0, 986, 1], [ 2884, 0, 63, 35, 0, 295], [ 3259, 0, 21208, 1, 29999, 4596], [ 19, 87, 93, 17, 124, 33], [ 762, 6, 75, 69, 3, 6051], [ 466, 29999, 14, 1217, 29252, 1], [23471, 20947, 3, 15, 15, 4], [ 42, 418, 215, 1887, 106, 0], [ 25, 8017, 14104, 6962, 1, 2039], [ 2, 0, 4998, 0, 2337, 27], [29999, 33, 17, 4797, 154, 9199], [ 3, 8, 20, 360, 4, 549], [ 63, 0, 956, 17, 738, 237], [18393, 17, 5, 187, 1812, 2], [ 15, 24879, 5332, 0, 5332, 2873], [ 3855, 1879, 9754, 303, 6, 0], [ 0, 717, 19, 6867, 143, 10], [ 796, 46, 38, 611, 4040, 69], [ 15, 7, 7, 6, 12, 7], [ 0, 574, 2500, 1681, 6476, 5], [24664, 6351, 336, 36, 1011, 30], [ 109, 146, 0, 9640, 4, 100], [ 18, 102, 27813, 2648, 8, 5062], [ 7, 7, 7, 7, 548, 151], [ 702, 124, 15, 3, 1710, 6], [ 161, 31, 3692, 56, 3371, 487], [ 9, 22, 22, 15, 8, 9], [ 5, 15146, 6872, 29999, 0, 6617], [ 32, 1952, 11, 267, 36, 988], [ 7, 3, 8, 16, 10123, 1052], [ 115, 34, 19711, 0, 19711, 1696], [ 4763, 72, 3, 9, 12, 3], [ 74, 31, 195, 0, 131, 9], [ 4317, 3652, 10, 2683, 1950, 87], [ 135, 48, 1, 296, 559, 488], [ 13, 770, 4, 1271, 2752, 14], [ 7, 7, 4, 3032, 21, 16], [ 26, 909, 2175, 2157, 7098, 3073], [29999, 84, 80, 9183, 4937, 84], [12515, 2446, 334, 0, 228, 469], [ 0, 252, 19, 30, 395, 1377], [27175, 2793, 2686, 29999, 39, 3184], [ 5926, 2, 29999, 1543, 113, 39], [ 196, 103, 256, 219, 2892, 5], [ 415, 20568, 19, 7434, 4395, 19], [ 643, 33, 47, 131, 83, 3041], [ 139, 11, 46, 3378, 43, 546], [ 3, 8, 22, 3, 8, 22], [ 168, 29999, 4, 9, 3, 9], [ 0, 9, 20, 1, 522, 6825], [29999, 29999, 29999, 3, 8, 8], [ 7, 3, 8, 7, 62, 33], [ 879, 289, 18, 1881, 5, 45], [ 3138, 18947, 37, 2749, 34, 869], [ 273, 18, 466, 2, 0, 21473], [ 231, 2467, 55, 1557, 115, 103], [ 5183, 1341, 772, 28, 297, 423], [ 1989, 0, 4091, 179, 29999, 209], [ 2645, 11, 158, 832, 2, 556], [ 17, 601, 1174, 31, 7189, 26], [ 303, 5280, 1511, 25, 0, 3176], [ 743, 3, 12, 22, 3, 8], [ 63, 5, 932, 5046, 1782, 17], [ 2505, 1, 16297, 2090, 530, 785], [ 904, 3, 22, 7, 324, 3], [ 0, 194, 6603, 48, 1143, 32], [ 49, 26787, 120, 26, 69, 0], [ 117, 3, 8, 20, 16, 22], [ 12, 12, 42, 1, 0, 120], [ 1, 3640, 46, 23, 52, 9218], [ 330, 194, 8839, 11850, 3811, 2], [ 16, 12, 30, 1, 29999, 0], [ 915, 2, 6, 148, 606, 8534], [ 22, 3, 20, 20, 16, 3], [ 43, 425, 4, 18482, 58, 25], [ 111, 23, 2067, 1290, 4, 544], [ 405, 85, 0, 1, 50, 16], [17000, 483, 5, 10, 420, 13], [ 1, 0, 52, 78, 11046, 4], [29999, 607, 639, 4, 458, 9], [ 1625, 23748, 1948, 22018, 23, 29999], [ 1, 0, 5176, 2223, 520, 5585], [ 3, 20, 17, 2677, 115, 13], [ 316, 13, 2508, 4, 544, 909], [ 3694, 5493, 486, 145, 3109, 759], [ 178, 0, 3728, 1, 11821, 295], [ 8, 3, 15, 9757, 17544, 4319], [ 6, 5581, 2, 4700, 3564, 64], [ 5766, 10352, 370, 692, 9, 7], [ 27, 30, 1383, 1, 4736, 0], [ 492, 4, 68, 8, 12, 7], [ 509, 3, 7, 6, 1654, 16], [ 3, 8, 16, 2, 3, 8], [ 0, 691, 1, 29999, 26, 160], [10949, 29999, 0, 1, 0, 3207], [ 71, 82, 70, 646, 75, 125], [ 4, 3299, 107, 2, 3490, 1], [ 828, 14648, 4, 330, 277, 1], [ 3312, 62, 632, 44, 4414, 18], [ 15, 3, 22, 9, 16, 8018], [ 70, 2347, 1678, 321, 4501, 70]]) tensor([[ 49, 600, 192, ..., 8, 2511, 346], [ 419, 28, 1657, ..., 8, 29999, 29999], [ 395, 4000, 707, ..., 715, 501, 4], ..., [ 1, 6, 0, ..., 94, 16, 2011], [ 1, 651, 2439, ..., 2007, 2533, 29999], [ 19, 149, 0, ..., 322, 1110, 29999]]) tensor([ 0, 2, 4, 639, 16, 46, 0, 586, 29999, 8, 768, 16, 1193, 5799, 2742, 21, 0, 9, 592, 1, 0, 1227, 5, 19147, 4886, 5, 2, 423, 1, 29999, 1402, 1351, 8, 682, 27, 14, 279, 3, 0, 12738, 291, 42, 0, 15221, 6, 13, 28, 288, 29999, 490, 49, 15922, 122, 1, 29999, 247, 4, 416, 11035, 22725, 7, 0, 371, 2, 1447, 3366, 29999, 1, 3731, 3974, 1, 68, 598, 782, 619, 4, 3465, 1266, 2507, 29999, 645, 3280, 1739, 4, 37, 7130, 38, 15, 1029, 1314, 30, 4, 219, 17848, 9703, 0, 10, 0, 821, 654, 2, 0, 163, 1818, 3401, 31, 29999, 6968, 14, 0, 5, 6, 36, 1, 178, 1, 2, 8386, 1810, 25037, 2, 25, 255, 18, 1, 29999, 3989, 7394]) tensor([[ 7312, 584, 98, 40, 1898, 30], [29999, 1178, 3594, 799, 4615, 1], [ 885, 39, 432, 0, 231, 2085], [ 2, 9176, 4, 28349, 315, 2], [ 3, 8, 8, 2895, 5, 94], [ 701, 29999, 28, 51, 31, 2399], [ 1850, 82, 747, 784, 1, 0], [ 10, 36, 5, 2, 3095, 38], [ 5, 457, 1, 12358, 7160, 18], [ 12, 8, 8, 1981, 467, 860], [ 3798, 1, 147, 185, 0, 333], [ 4613, 2, 3, 42, 642, 80], [ 1787, 478, 652, 1714, 2, 239], [ 0, 400, 351, 4, 21707, 2544], [ 19, 1668, 4, 5599, 1940, 2846], [ 20, 1632, 3205, 3, 22, 9], [ 0, 1114, 1, 1563, 2, 1730], [29999, 29999, 29999, 7, 7, 7], [24326, 9658, 122, 3, 8, 16], [ 10, 5, 143, 1283, 19, 10], [ 4, 0, 71, 290, 3719, 3], [ 23, 5, 29999, 4185, 91, 89], [ 40, 2920, 11, 234, 4062, 444], [ 3155, 1, 5, 109, 146, 0], [29999, 1, 0, 9693, 2882, 529], [29999, 2139, 8300, 10, 37, 86], [29999, 539, 1821, 2458, 73, 3], [ 293, 3278, 6, 7628, 41, 4317], [ 1, 0, 8731, 0, 1821, 1259], [29999, 610, 14, 2231, 2798, 3175], [29999, 155, 1756, 4, 65, 591], [ 1, 65, 25, 217, 1649, 2], [ 85, 3, 8, 21, 76, 0], [ 179, 1, 164, 24, 9, 7], [ 768, 2, 2018, 0, 9733, 4], [ 1507, 1, 29999, 1507, 29999, 327], [ 3349, 1529, 17952, 9, 341, 1403], [ 206, 3, 1188, 8, 3, 3], [ 19, 1862, 18, 202, 5, 238], [ 604, 1722, 28764, 810, 3046, 2817], [ 24, 269, 1, 28, 728, 20483], [ 483, 6, 0, 24, 0, 3], [29999, 2, 195, 101, 1, 23172], [ 39, 417, 353, 23525, 5843, 28], [ 10, 36, 1462, 46, 47, 5], [ 6, 29, 6286, 211, 9, 2011], [ 1, 671, 10, 275, 31, 121], [ 339, 13848, 19, 4, 545, 9], [ 199, 92, 1, 13518, 6, 5], [ 1190, 193, 2, 178, 29999, 35], [ 1158, 3, 28, 2772, 2160, 23], [ 37, 1791, 212, 478, 15922, 559], [29999, 19796, 105, 187, 28, 4410], [ 495, 0, 27209, 30, 1372, 1163], [ 192, 46, 25, 2, 24540, 2], [ 109, 146, 447, 16395, 10670, 29468], [ 147, 3482, 2, 549, 1808, 157], [ 173, 29999, 43, 213, 36, 76], [ 5, 9, 5561, 3643, 781, 3643], [24853, 44, 12066, 37, 1173, 29999], [28163, 484, 9, 7, 9, 497], [ 2, 1380, 18, 1230, 310, 0], [ 30, 1029, 68, 48, 63, 11], [ 167, 603, 147, 31, 603, 6968], [ 23, 5, 494, 29999, 19, 335], [21385, 587, 0, 1119, 10, 30], [ 9226, 4, 116, 4, 0, 291], [ 80, 4, 459, 44, 5568, 11], [ 1, 26924, 142, 17, 186, 356], [ 45, 17, 5, 1, 284, 1951], [ 79, 3, 343, 57, 1428, 6], [ 1180, 98, 46, 66, 31, 3119], [ 1051, 1027, 6398, 2959, 14, 29999], [ 9620, 46, 12880, 93, 2007, 23], [ 205, 167, 36, 1423, 58, 25], [ 2, 634, 1824, 9, 7, 7], [11057, 817, 10302, 211, 0, 1203], [ 0, 12412, 234, 1, 4465, 311], [ 21, 7, 7, 22, 12, 7], [ 33, 1895, 23, 29999, 2, 133], [ 195, 24, 0, 11, 0, 5476], [ 1278, 1209, 6, 111, 27, 0], [ 6371, 19, 5, 47, 908, 3265], [ 235, 405, 3466, 5567, 13254, 19], [13561, 41, 10, 10922, 0, 10922], [ 22, 29999, 12448, 479, 28965, 73], [ 107, 1, 35, 43, 201, 2090], [ 0, 178, 109, 7, 845, 0], [ 173, 1008, 9741, 660, 1436, 182], [ 23, 0, 6179, 1, 4128, 842], [ 550, 316, 60, 1487, 3936, 7674], [ 25, 160, 513, 0, 1849, 4887], [ 6624, 4, 0, 276, 4, 52], [ 2194, 17379, 1, 1614, 4, 5], [29999, 238, 4, 3, 8, 16], [ 108, 3690, 24, 920, 375, 15170], [15347, 15371, 2966, 30, 241, 1711], [ 5593, 29999, 24206, 947, 3006, 4], [ 1811, 4, 61, 1380, 18, 473], [ 1, 187, 10, 22244, 18, 347], [ 1, 361, 3312, 330, 29999, 3610], [ 4273, 2, 1181, 57, 11847, 1], [ 0, 2950, 250, 1057, 84, 5706], [ 444, 30, 29999, 259, 19, 3334], [ 3, 226, 7404, 2139, 72, 3], [ 2936, 2747, 161, 2411, 64, 5], [ 867, 16747, 2, 4, 549, 81], [ 837, 10, 76, 2, 56, 72], [ 989, 598, 811, 22407, 92, 10], [ 19, 909, 845, 3167, 1, 0], [ 618, 15522, 11, 348, 13, 83], [ 55, 673, 24, 5, 855, 538], [ 2, 3480, 17, 4124, 1429, 6], [ 11, 5, 3806, 29999, 2, 29999], [ 7, 14, 490, 18904, 0, 375], [ 28, 79, 319, 0, 1839, 18476], [ 3316, 8058, 6485, 4175, 836, 40], [ 8, 21, 0, 690, 301, 971], [ 1668, 4, 13742, 1, 946, 2552], [ 15, 16, 6084, 23092, 10213, 1862], [ 29, 16, 6412, 29999, 14780, 6112], [ 20, 2207, 277, 29999, 77, 9], [ 357, 1, 5, 524, 1175, 5], [ 523, 1, 9470, 6530, 478, 1], [ 5, 634, 863, 4150, 1583, 14], [ 137, 1, 5, 4, 5, 4044], [ 2518, 73, 8433, 29999, 2, 15104], [ 0, 8595, 1, 40, 53, 6398]]) tensor([[ 145, 14, 5093, ..., 32, 5613, 4], [ 27, 28, 29999, ..., 843, 1, 22], [ 71, 18, 17354, ..., 2574, 1, 50], ..., [ 2736, 338, 1649, ..., 19324, 309, 6], [ 6, 0, 1218, ..., 3399, 594, 77], [ 377, 1768, 11, ..., 3, 2, 13]]) tensor([ 469, 41, 88, 5, 889, 3089, 106, 0, 365, 9, 29999, 981, 980, 13, 2, 6325, 0, 0, 99, 363, 2, 3557, 308, 1270, 4474, 29999, 4082, 3310, 1827, 19417, 1268, 204, 0, 22, 38, 4544, 11, 0, 1, 6, 309, 8363, 903, 13397, 9, 5517, 0, 2786, 73, 267, 10354, 19, 465, 2, 28, 18180, 12, 1531, 14, 4, 7517, 139, 931, 2, 9675, 1, 24, 150, 184, 5197, 37, 123, 3, 3, 26, 2065, 1373, 13, 2465, 4329, 132, 22, 13, 3228, 0, 8287, 615, 2478, 130, 1, 29999, 21, 15, 16, 0, 6788, 9517, 18483, 0, 7, 29999, 1119, 4904, 1514, 3, 8084, 459, 0, 3162, 3, 95, 1, 10, 107, 1607, 8, 1199, 105, 1, 29999, 3014, 82, 2, 14, 132, 1, 833, 4458]) tensor([[ 1632, 24, 20, 3, 12, 12], [ 6, 89, 111, 667, 4, 3], [ 5220, 0, 45, 12841, 341, 4117], [ 6, 26, 11, 143, 1, 12144], [ 434, 597, 657, 24, 0, 2190], [ 355, 10888, 1030, 0, 29999, 17], [ 33, 47, 3168, 3793, 19, 134], [ 4, 410, 2, 9, 1, 111], [ 3259, 18, 61, 105, 149, 2311], [ 7, 7, 7, 7, 7, 7], [ 54, 11, 1236, 104, 251, 6075], [ 14, 2623, 2199, 0, 472, 1581], [ 1, 4360, 67, 3, 8, 8], [ 0, 359, 488, 6312, 6566, 1275], [29999, 367, 3543, 3566, 23, 3223], [ 22, 9, 3863, 2603, 1, 73], [ 14, 2168, 1, 29999, 1, 0], [ 2333, 3067, 2354, 2434, 5456, 0], [ 117, 7, 128, 128, 10, 0], [ 1, 2389, 5642, 28, 10038, 48], [ 117, 128, 3, 117, 128, 9], [ 0, 29999, 46, 32, 10, 564], [ 6, 0, 4380, 2320, 24, 0], [ 1668, 4, 5, 2494, 2, 30], [ 42, 13, 137, 40, 49, 5288], [ 2, 450, 848, 10, 181, 4], [ 2, 12733, 471, 0, 29999, 47], [12149, 29999, 0, 911, 3, 8], [ 41, 432, 0, 2, 783, 1], [ 937, 19117, 29999, 0, 438, 1], [ 109, 158, 317, 6, 0, 19400], [ 54, 11, 15041, 2906, 360, 2939], [ 491, 611, 69, 29999, 16, 10], [ 7, 3, 9, 20, 6, 3], [ 236, 3149, 478, 2920, 118, 0], [ 8833, 6, 441, 14, 5, 22586], [ 0, 10293, 1345, 12819, 684, 60], [ 42, 7937, 24, 1721, 2, 0], [ 351, 4836, 681, 4709, 29999, 0], [ 38, 489, 156, 7383, 3, 1575], [ 86, 13, 0, 726, 27, 29999], [ 1946, 948, 4, 478, 11417, 5], [ 164, 2847, 791, 14218, 593, 2460], [ 7685, 3830, 6, 0, 3502, 55], [ 7, 7, 1666, 15, 7, 7], [ 2, 1552, 1717, 97, 24, 0], [ 4602, 28, 19, 519, 5832, 74], [ 2786, 0, 1624, 1624, 1592, 5], [ 128, 9, 6724, 16, 128, 159], [ 0, 21206, 794, 21206, 40, 75], [ 7579, 24652, 29999, 2, 8494, 12774], [ 5, 379, 2565, 0, 675, 726], [ 219, 0, 61, 82, 3, 8], [ 669, 336, 295, 284, 472, 5339], [ 25, 958, 3997, 18536, 6, 18], [ 411, 1440, 29999, 55, 10, 0], [ 968, 9, 20, 7664, 667, 23], [ 5867, 1, 0, 1, 30, 4151], [ 1414, 14, 29999, 191, 4, 0], [ 3798, 10, 3211, 0, 272, 24], [ 7, 21, 3815, 231, 301, 2467], [ 29, 4117, 4973, 216, 33, 3421], [ 0, 1477, 19, 17, 1521, 383], [29999, 29999, 29999, 29999, 29999, 60], [ 355, 43, 201, 35, 4, 48], [ 219, 0, 2197, 0, 1497, 4], [ 7299, 15056, 541, 919, 16, 22], [ 2279, 4, 0, 14, 2, 446], [ 184, 6142, 62, 1554, 70, 2074], [ 4, 6812, 32, 34, 1723, 1080], [ 1129, 168, 21868, 355, 5, 1481], [14526, 19, 1118, 0, 4019, 6], [ 4539, 29999, 209, 8, 21, 8], [ 3, 8, 22, 33, 17, 432], [ 177, 1, 505, 10, 0, 3372], [ 35, 17, 186, 63, 32, 1473], [ 553, 1, 0, 12193, 51, 31], [ 5, 449, 183, 3159, 154, 3204], [ 538, 160, 5, 49, 6445, 22543], [ 8112, 29999, 28, 0, 92, 8112], [ 1301, 25, 0, 326, 4, 263], [ 3, 22, 8, 163, 4, 2899], [ 7274, 3580, 2692, 29999, 91, 3688], [ 90, 119, 133, 24, 8457, 975], [ 53, 2278, 27, 3819, 200, 34], [ 27, 29, 9, 66, 5, 1130], [ 16, 146, 6008, 622, 1182, 6539], [ 444, 13, 0, 1213, 2140, 125], [ 152, 26, 17, 6, 31, 9426], [ 3022, 0, 95, 0, 438, 4], [ 9, 12, 4854, 100, 6755, 72], [ 153, 741, 16, 16, 22, 3], [15768, 1424, 155, 15, 29999, 9], [ 9, 7, 7, 0, 10050, 4656], [ 1177, 6, 705, 342, 385, 5], [ 12, 29999, 289, 4361, 75, 3], [ 1, 0, 679, 1, 0, 3], [ 19, 2395, 96, 18, 5, 2792], [ 7, 7846, 3948, 609, 52, 1], [ 223, 34, 128, 41, 26, 40], [ 8, 9, 16, 64, 5, 178], [ 24, 0, 542, 1, 0, 45], [ 8650, 2, 16933, 3539, 0, 7187], [ 2309, 6, 761, 14652, 1, 675], [ 1, 0, 72, 22, 39, 9232], [ 113, 196, 51, 58, 10, 521], [ 18, 407, 739, 13, 4476, 214], [ 21, 3, 9, 500, 436, 2], [ 5, 1632, 400, 927, 191, 34], [ 1184, 15, 22, 3769, 25, 11584], [ 265, 5, 3254, 2, 39, 18622], [ 1549, 86, 6795, 0, 57, 1683], [ 99, 0, 13281, 78, 16, 7], [12402, 1016, 18, 6434, 2, 227], [ 17, 6, 371, 81, 4, 3], [ 3, 8, 7, 1431, 56, 100], [ 62, 2052, 45, 28316, 4, 2052], [ 21, 7, 16, 19, 1283, 0], [ 11, 0, 89, 0, 29999, 33], [ 0, 911, 29999, 2, 484, 109], [ 669, 3507, 18, 7612, 249, 11], [ 197, 1, 0, 3, 22, 8], [ 577, 6, 3128, 21252, 18, 0], [ 0, 193, 2696, 607, 1976, 4675], [ 6192, 13, 0, 1602, 51, 293], [ 102, 13, 2237, 3264, 111, 4], [ 75, 792, 161, 4067, 3318, 1], [ 2, 5582, 6, 20373, 2, 3928]]) tensor([[ 32, 37, 276, ..., 29999, 30, 17], [ 14, 2, 25, ..., 23, 9077, 159], [ 21, 1714, 12, ..., 10, 680, 9], ..., [ 2525, 13, 37, ..., 33, 1831, 11], [ 5, 7315, 34, ..., 108, 23, 147], [ 0, 0, 15665, ..., 6368, 1104, 19705]])- 把所有text编码成数字,然后用
3.2.3 Define Embedding model
创建
Embedding类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embed_size):
''' 初始化输出和输出embedding
'''
super(EmbeddingModel, self).__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
initrange = 0.5 / self.embed_size
self.out_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
self.out_embed.weight.data.uniform_(-initrange, initrange)
self.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
self.in_embed.weight.data.uniform_(-initrange, initrange)
def forward(self, input_labels, pos_labels, neg_labels):
'''
input_labels: 中心词, [batch_size]
pos_labels: 中心词周围 context window 出现过的单词 [batch_size * (window_size * 2)]
neg_labelss: 中心词周围没有出现过的单词,从 negative sampling 得到 [batch_size, (window_size * 2 * K)]
return: loss, [batch_size]
'''
batch_size = input_labels.size(0)
input_embedding = self.in_embed(input_labels) # B * embed_size, [batch_size, embed_size]
pos_embedding = self.out_embed(pos_labels) # B * (2*C) * embed_size, [batch_size, embed_size]
neg_embedding = self.out_embed(neg_labels) # B * (2*C * K) * embed_size, [batch_size, (window_size * 2 * k), embed_size]
# input_embedding = input_embedding.unsqueeze(2) # [batch_size, embed_size, 1]
log_pos = torch.bmm(pos_embedding, input_embedding.unsqueeze(2)).squeeze() # B * (2*C), [batch_size, (window_size * 2)]
log_neg = torch.bmm(neg_embedding, -input_embedding.unsqueeze(2)).squeeze() # B * (2*C*K), [batch_size, (window_size * 2 * k)]
log_pos = F.logsigmoid(log_pos).sum(1)
log_neg = F.logsigmoid(log_neg).sum(1) # batch_size
loss = log_pos + log_neg
return -loss
def input_embeddings(self):
return self.in_embed.weight.data.cpu().numpy()实例化模型并移动到
GPU1
2
3model = EmbeddingModel(VOCAB_SIZE, EMBEDDING_SIZE)
if USE_CUDA:
model.cuda()模型训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19optimizer = torch.optim.SGD(model.parameters(), lr = LEARNING_RATE)
for e in range(NUM_EPOCHS):
for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):
input_labels = input_labels.long()
pos_labels = pos_labels.long()
neg_labels = neg_labels.long()
if USE_CUDA:
input_labels = input_labels.cuda()
pos_labels = pos_labels.cuda()
neg_labels = neg_labels.cuda()
optimizer.zero_grad()
loss = model(input_labels, pos_labels, neg_labels).mean()
loss.backward()
optimizer.step()
if i%10000 == 0:
print('epoch', e, 'iteration', i, loss.cpu().item())epoch 0 iteration 0 420.04754638671875 epoch 0 iteration 10000 37.9792366027832 epoch 0 iteration 20000 33.68553924560547 epoch 0 iteration 30000 33.009620666503906 epoch 0 iteration 40000 33.17190170288086 epoch 0 iteration 50000 32.391265869140625 epoch 0 iteration 60000 32.888916015625 epoch 0 iteration 70000 32.370094299316406 epoch 0 iteration 80000 32.19983673095703 epoch 0 iteration 90000 31.926647186279297 epoch 0 iteration 100000 32.60920715332031 epoch 0 iteration 110000 32.57024383544922 epoch 1 iteration 0 31.93549346923828 epoch 1 iteration 10000 32.00389862060547 epoch 1 iteration 20000 32.29582214355469 epoch 1 iteration 30000 32.100887298583984 epoch 1 iteration 40000 32.123470306396484 epoch 1 iteration 50000 31.802623748779297 epoch 1 iteration 60000 32.11222839355469 epoch 1 iteration 70000 32.37131881713867 epoch 1 iteration 80000 31.90352439880371 epoch 1 iteration 90000 31.634069442749023 epoch 1 iteration 100000 31.78694725036621 epoch 1 iteration 110000 32.359596252441406保存参数
1
2embedding_weights = model.input_embeddings()np.save("/content/drive/MyDrive/Word_embedding/embedding-{}".format(EMBEDDING_SIZE), embedding_weights)
torch.save(model.state_dict(), "/content/drive/MyDrive/Word_embedding/embedding-{}.th".format(EMBEDDING_SIZE))加载保存的模型
1
model.load_state_dict(torch.load("/content/drive/MyDrive/Word_embedding/embedding-{}.th".format(EMBEDDING_SIZE)))
模型评估
下面是评估模型的代码,以及训练模型的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def evaluate(filename, embedding_weights):
if filename.endswith(".csv"):
data = pd.read_csv(filename, sep=",")
else:
data = pd.read_csv(filename, sep="\t")
human_similarity = []
model_similarity = []
for i in data.iloc[:, 0:2].index:
word1, word2 = data.iloc[i, 0], data.iloc[i, 1]
if word1 not in word_to_idx or word2 not in word_to_idx:
continue
else:
word1_idx, word2_idx = word_to_idx[word1], word_to_idx[word2]
word1_embed, word2_embed = embedding_weights[[word1_idx]], embedding_weights[[word2_idx]]
model_similarity.append(float(sklearn.metrics.pairwise.cosine_similarity(word1_embed, word2_embed)))
human_similarity.append(float(data.iloc[i, 2]))
return scipy.stats.spearmanr(human_similarity, model_similarity)# , model_similarity
def find_nearest(word):
index = word_to_idx[word]
embedding = embedding_weights[index]
cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])
return [idx_to_word[i] for i in cos_dis.argsort()[:10]]训练模型步骤:
- 模型一般需要训练若干个
epoch - 每个
epoch我们都把所有的数据分成若干个batch - 把每个
batch的输入和输出都包装成 cuda tensor - forward pass,通过输入的句子预测每个单词的下一个单词
- 用模型的预测和正确的下一个单词计算 cross entropy loss
- 清空模型当前
gradient - backward pass
- 更新模型参数
- 每隔一定的
iteration输出模型在当前iteration的loss,以及在验证数据集上做模型的评估
- 模型一般需要训练若干个
3.2.4 在测试集上进行模型评估
本例中,使用 MEN 和 Simplex-999 数据集进行样本外评估
加载数据和评估
1
2
3
4embedding_weights = model.input_embeddings()
print("simlex-999", evaluate("/content/drive/MyDrive/Word_embedding/simlex-999.txt", embedding_weights))
print("men", evaluate("/content/drive/MyDrive/Word_embedding/men.txt", embedding_weights))
print("wordsim353", evaluate("/content/drive/MyDrive/Word_embedding/wordsim353.csv", embedding_weights))Results:
simlex-999 SpearmanrResult(correlation=0.16835319824603753, pvalue=1.6908393994875427e-07) men SpearmanrResult(correlation=0.18093374889038655, pvalue=1.9329614120922215e-20) wordsim353 SpearmanrResult(correlation=0.28416412711604, pvalue=2.440437723067791e-07)
3.2.5 Look for nearest neighbors
相似度分析
查找与给定单词最相关的词:
1
2for word in ["good", "fresh", "monster", "green", "like", "america", "chicago", "work", "computer", "language"]:
print(word, find_nearest(word))good ['good', 'bad', 'experience', 'future', 'hard', 'perfect', 'truth', 'money', 'love', 'personal'] fresh ['fresh', 'grain', 'dense', 'lighter', 'sized', 'waste', 'noise', 'drinking', 'colour', 'concrete'] monster ['monster', 'golem', 'giant', 'vampire', 'melody', 'cube', 'jaguar', 'finger', 'rod', 'horn'] green ['green', 'blue', 'yellow', 'white', 'cross', 'red', 'black', 'orange', 'gold', 'mountain'] like ['like', 'etc', 'rich', 'soft', 'unlike', 'similarly', 'bear', 'animals', 'sounds', 'fish'] america ['america', 'africa', 'korea', 'india', 'australia', 'indian', 'europe', 'turkey', 'asia', 'pakistan'] chicago ['chicago', 'boston', 'texas', 'london', 'illinois', 'berkeley', 'florida', 'massachusetts', 'indiana', 'austin'] work ['work', 'writing', 'job', 'marx', 'recording', 'writings', 'speech', 'vision', 'label', 'ideas'] computer ['computer', 'digital', 'software', 'audio', 'electronic', 'video', 'hardware', 'computers', 'graphics', 'programs'] language ['language', 'languages', 'alphabet', 'arabic', 'spoken', 'programming', 'grammar', 'pronunciation', 'dialects', 'dialect']
3.2.6 单词之间的关系
1 | man_idx = word_to_idx["man"] |
king
henry
charles
queen
pope
iii
edward
elizabeth
prince
alexander
constantine
james
son
louis
iv
mary
william
francis
albert
joseph理想的效果的是得到的结果是 queen
的词向量,可以发现出现在第四位,勉强能捕捉到这一信息,但精度还有待提高,这跟训练的次数和语料库大小有关。