1. Introduction
Blending 方法可以看是一个简化版的 Stacking 方法,blend 的中文意思是 “混合”,这就很好地诠释了 Blending 方法的思想 —— 不同模型的混合,也就是集成的本意。该方法仅在验证集中进行预测,如下为 Blending 的步骤:
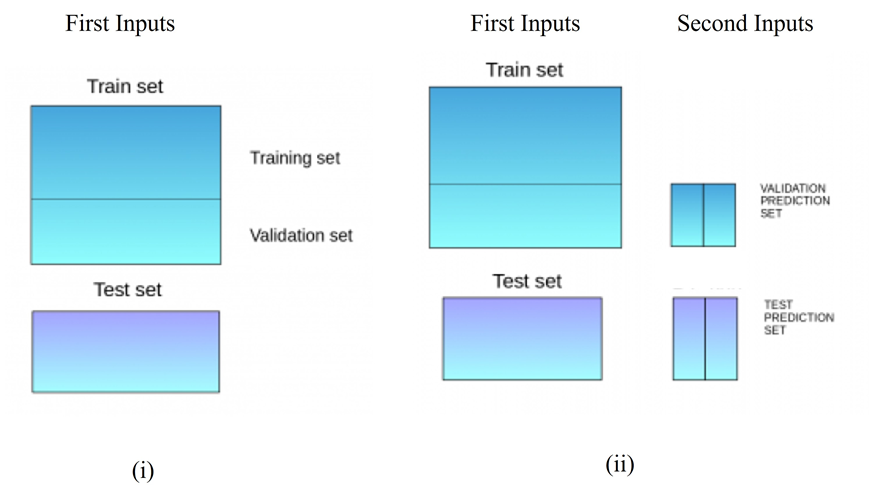
- 将数据划分为 train set 和 test set,其中,train set 需要进一步被细分为 Training set 和 validation set (见 Fig. 1 (i),图片来源:Analytics vidhya);
- 构建多个模型 (第一层),并使用细分后的 Training set 作为输入数据来训练这些模型,并用训练好的模型来预测 validation set 和 test set,得到 val_pred 和 test_pred;
- 再次构建模型(第二层),并将 val_pred 视为训练集来训练该层的模型(见 Fig. 1 (ii);
- 用训练好的模型来对测试集 (test_pred) 进行预测,得到预测结果 test prediction 记为整个 Blending 集成学习的预测结果。
2. Sample
2.1 Steps
为了对 Blending 有进一步的了解,参考 Analytics vidhya, 构建了一个两层的 Blending 模型,其中第一层由决策树和 KNN 组成,对这两个模型用 Training set 进行预测,并用训练好的模型预测 Valitation set 和 test set。之后构建一个逻辑回归利用上述两个预测结果进行预测训练。具体步骤如下:
Import Module
1
2
3
4
5
6
7
8
9
10
11import numpy as np
import pandas as pd
from sklearn import tree
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.datasets import make_blobsCreating Datasets
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16data, target = make_blobs(n_samples = 10000, centers = 2,
random_state = 1, cluster_std = 1.0 )
# Creatint test set and temporary train set, test_percent = 20%
x_train1,x_test,y_train1,y_test = train_test_split(data,
target, test_size = 0.2, random_state = 1)
# Spliting temporary train set into train set and validation set, validation_percent = 80%*30%
x_train,x_val,y_train,y_val = train_test_split(X_train1,
y_train1, test_size = 0.3, random_state = 1)
print("The shape of training X:", x_train.shape)
print("The shape of training y:", y_train.shape)
print("The shape of test set:", x_test.shape)
print("The shape of test y:", y_test.shape)
print("The shape of validation X:", x_val.shape)
print("The shape of validation y:", y_val.shape)Result:
1
2
3
4
5
6The shape of training X: (5600, 2)
The shape of training y: (5600,)
The shape of test set: (2000, 2)
The shape of test y: (2000,)
The shape of validation X: (2400, 2)
The shape of validation y: (2400,)First Layer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16model1 = tree.DecisionTreeClassifier()
model1.fit(x_train, y_train)
val_pred1=model1.predict(x_val)
test_pred1=model1.predict(x_test)
val_pred1=pd.DataFrame(val_pred1)
test_pred1=pd.DataFrame(test_pred1)
model2 = KNeighborsClassifier()
model2.fit(x_train,y_train)
val_pred2=model2.predict(x_val)
test_pred2=model2.predict(x_test)
val_pred2=pd.DataFrame(val_pred2)
test_pred2=pd.DataFrame(test_pred2)Second Layer
1
2
3
4df_val=pd.concat([pd.DataFrame(x_val), val_pred1, val_pred2],axis=1)
df_test=pd.concat([pd.DataFrame(x_test),test_pred1,test_pred2],axis=1)
model = LogisticRegression()
model.fit(df_val,y_val)Forecasting Results
1
2model.score(df_test,y_test)
cross_val_score(model,df_test,y_test,cv=10)Result:
1
21.0
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
2.2 Complete codes
1 | # Inporting modules |