1 Stata data operation
1.1 Data Operation
1.1.1 Browse data
browse / edit
browse用于打开或编辑数据浏览器,相当于单击数据浏览器或编辑按钮。命令格式:1
browse/edit [varlist] [if] [in]
rename
rename用于对变量重新命名。格式:1
rename (oldname) (newname)
save
save用于将内存中的数据保存到硬盘上。基本格式:1
save [filename] [, save_options]
1.1.2 Import data
导入原则:
打开新数据集之前,必须用
clear命令清除存在于内存中的数据集;如果某些数据集超出了现有的设定的内存空间,则需要使用
set memory来设定内存空间大小;使用
use命令读入 Stata 格式数据,使用edit命令输入数据;使用 excel 文件复制粘贴数据。
use
读取 Stata 自身数据的命令,基本语法:
1
2
3
4use filename [, clear nolabel]
// Clear: 指明目前内存中的数据尚未保存,仍然可以用新的数据来代替它
// Nolabel:在载入数据时不载入相关的标签
1.1.3 Descriptive commands
describedescribe用于产生一个对数据集的简明总结表格。输出的结果中包含每个变量的名称、存储方式(byte、float,double和int)、显示格式、变量标签和变量值标签。命令格式:1
2describe [varlist] [, memory_options]
d [varlist] [, memory_options]memory_options:
- simple(si): display only variable names;
- short(s): display only general information;
- fullnames(f): do not abbreviate variable names;
- numbers(n): display variable number along with name;
listlist用于显示变量的数值,其后可以跟需要显示的变量名称。如果没有设定变量,则默认显示所有的变量数值。命令格式:1
2list [varlist]] [if] [in] [, options]
l [varlist]] [if] [in] [, options]codebookcodebook用于详尽地描述变量的内容,包括变量名称、变量标签和变量的赋值。基本格式:1
codebook [varlist] [if] [in] [, options]
summarizesummarize命令计算并显示各种单变量摘要统计信息。如果未指定varlist,则计算数据集中所有变量的摘要统计信息。对于任何的数据分析,使用summarize命令进行数据的核对都是很有必要的,尤其对于缺失值、无效值、奇异值的探测都很有帮助。基本语法:1
summarize [varlist] [if] [in] [weight] [, options]
其中,
varlist表示需要统计的变量,if为样本条件,in为样本范围,weight为样本权重。tabstattabstat命令主要用于统计量组合,与summarize类似。基本语法:1
2
3
4
5
6
7
8
9
10
11tabstat varlist [if] [in] [weight] [, options]
/*
`options`选项中的 `stat` :示设定所需要的统计量,`col` :将结果报表转置。
统计量主要有平均数、观测值数目,求和,平均标准误差等。
*/
webuse wage
generate lwage = log(wage)
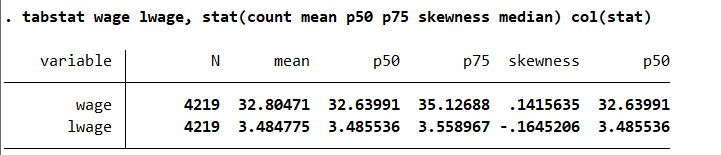
tabstat wage lwage, stat(count mean p50 p75 skewness median)
tabstat wage lwage, stat(count mean p50 p75 skewness median) col(stat)
tabstat wage lwage, by(married) stat(count mean p50 p75 skewness median) col(stat)Result:
1.1.4 Merge data
Horizontal merge
横向合并是指将两个数据文件的变量加总在一起。合并后数据的样本不变,但变量的数目增加了,使得数据文件变宽。横向合并的两个数据的样本是一样的,只是被存储在不同的数据文件里。横向合并主要通过命令
merge完成。基本语法:1
2
3merge [varlist] using filename [filename...][, option]
merge 1: 1 make using autocost // 对make变量进行1比1合并autocost文件Vertical Merge
纵向合并指的是把两个数据的样本加总在一起,合并后的数据变量数目不变,但样本数增加了,使得数据变长了。
最常见的纵向合并情况是使用同样的问卷在不同地方或不同时间调查得来的数据。合并步骤主要包括:
- 两个数据文件里相同变量的变量名要一致
- 两个数据文件里相同变量的变量数目一致
- 两个数据文件里个案序号不能重复
- 每个数据要生成一个新的变量来辨别合并后该数据的样本
1
2
3append using filename [filename...][, option]
merge 1: 1 make using autocost // 对make变量进行1比1合并autocost文件Cross Merge
交叉合并指的是把一个数据的个案和另外一个数据的个案交叉搭配生成新的数据。从数据的结构和用途上讲,交叉合并要比纵向和横向合并更加复杂。交叉合并有两类:
组内交叉:
joinby命令;1
2
3
4
5
6
7
8
9joinby [varlist] using filename [, options]
webuse child
webuse parent
descirbe
list, sep(0)
sort family_id
joinby family_id using https://www.stata-press.com/data/r16/child
// 组内合并,将 child 文件中的多余数据交叉合并到 parent中,重复的变量以parent为准一一交叉:
cross命令。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22cross using filename
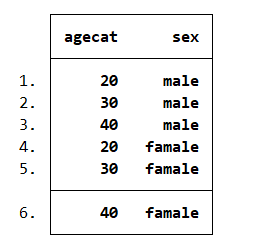
input str6 sex // create sex dataset
/*
sex variable:
sex
1\. male
2\. female
then, save sex dataset and drop it from memory
*/
input agecat // create agecat dataset
/*
agecat
1\. 20
2\. 30
3\. 40
*/
cross using sex //
listResult:
1.1.5 Data extraction
对于一些大型的数据,如人口普查数据和计算机记录的市场交易数据,因为其样本量太大,不适宜直接进行分析。最常用的方法是从数据中随机抽取一个样本,然后对样本进行分析,通常使用
sample 命令完成。语法格式:
1 | sample # [if] [in] [, count by (groupvars)]~~~~ |
1.1.6 数据处理
z 得分
Z得分,也叫标准分数(standard score),是一个数与平均数的差再除以标准差的过程。在统计学中,标准分数是一个观测或数据点的值高于被观测值或测量值的平均值的标准差的符号数。等于一个观测值是否异常最方便的方法就是计算Z得分。根据切比雪夫法则,不论数据的分布是什么形状,都至少有
3/4的测量值落在平均值的两个标准差的范围内,至少有8/9的测量值落在均值的三个标准差范围内。1
2
3
4webuse wage
quietly summarize wage
generate z = (wage - r(mean))
list wage z if z > 3箱线图
箱线图在数据探索中有巨大的作用。箱线图一般指箱型图。箱型图 (
Box-plot) 又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。在各种领域也经常被使用,常见于品质管理。它主要用于反应原始数据分散的特征。基本语法:1
2
3
4
5
6
7graph box yvars [if] [in] [weight] [, options]
graph hbox yvars [if] [in] [weight] [, options]
webuse wage
graph box wage
graph hbox wage, over(married)
graph hbox wage, over(married, sort(l))Result:
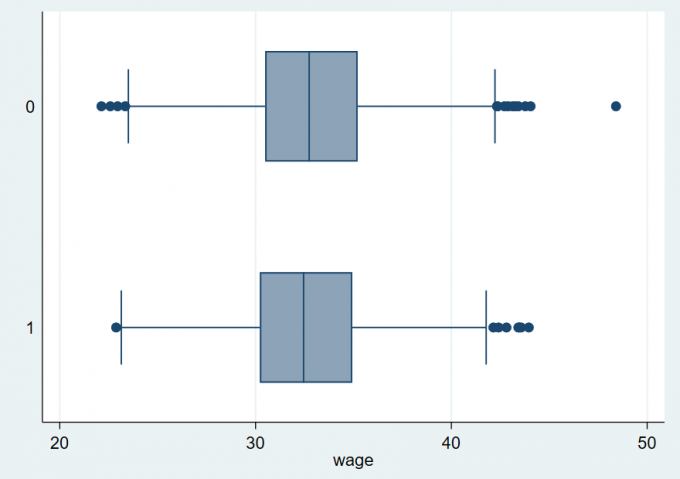
Fig 箱型图
分位正态图
利用分位正态图可以判断一个变量的分布是否近似于正态。基本语法:
Result:1
2
3
4qnorm varname [if] [in] [, options]
webuse wage
qnorm wage, grid
Fig 分位正态图
命令独有的选项是
grid。加入grid选项可以在图中依次标注 0.05、0.10、0.25、0.50、0.75、0.90、0.95 百分位数的坐标刻度。分位正态图将观测变量分布的分位数 (y轴) 与一个具有相同平均数和标准查的理论正态分布的分位数进行比较 (x轴),这样可以就变量分布的每个部分对正态性的偏离进行直观的审查。偏度-峰度正态性统计检验
偏度衡量随机变量概率分布的不对称性,是相对于平均值不对称程度的度量,通过对偏度系数的测量,我们能够判定数据分布的不对称程度以及方向。
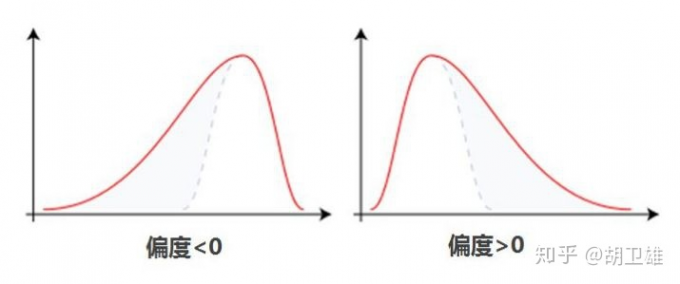
Fig 偏度
峰度,是研究数据分布陡峭或平滑的统计量,通过对峰度系数,可以判定数据相对于正态分布而言是更陡峭还是平缓。
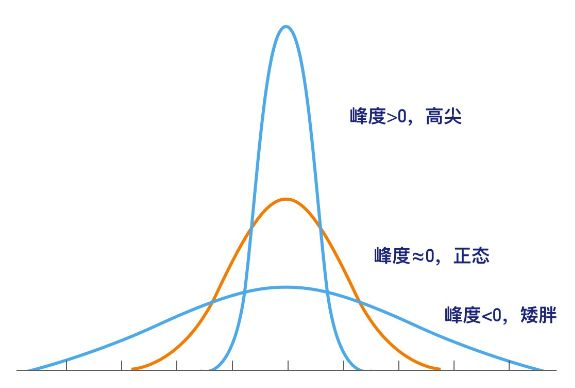
Fig 峰度
基本语法:
1
2
3
4sktest varlist [if] [in] [weight] [, noadjust]
webuse wage
sktest tenureResult:

Fig. 偏度-峰度检验
其中,
kurtosis的P值检验为 0,落入拒绝域,说明不满足正态分布(P值检验口诀:大同小异。小于 0.0000,说明落入拒绝域)。Shapiro-WilkW统计检验夏皮罗-威尔克检验 (
shapiro-wilk test) 是一种在频率上统计检验中检验正态性的方法。它在 1965 年由夏皮罗和威尔克发表。W检验基本语法:1
swilk varlist [if] [in] [, options]
Pearson相关系数Pearson相关系数又叫相关系数或自相关系数,一般用字母r表示,由两个变量的样本取值得到。是关于描述性相关强度的量,取值于-1和1之间。当两个变量有很强的线性相关时,相关系数接近于1(正相关) 或-1(负相关)。correlate命令计算变量之间的Pearson相关系数或者协方差矩阵,如果不指定变量,则默认对数据集中的所有变量计算响应的矩阵。pwcorr命令的好处是尽可能使用两两变量中所有没有缺失的数据,而不像correlate只采用没有任何缺失数据的完整的观测值。基本命令:1
2
3
4
5
6
7correlate [varlist] [if] [in] [weight] [, correlate_options]
pwcorr [varlist] [if] [in] [weight] [, pwcorr_options]
webuse wage
correlate wage hours tenure // 相关系数
correlate wage hours tenure, covariance // 协方差
pwcorr wage hours tenure, sig star(.05) print(.05)Spearman相关系数Spearman相关系数是衡量两个变量的依赖性的非参数指标。它利用单调方程评价两个统计变量的相关性。不管变量之间的关系是不是线性的,只要变量之间具有严格的单调增加的函数关系,变量之间的斯皮尔曼相关系数就是1。如果数据中没有重复值,并且当两个变量完全单调相关时,斯皮尔曼相关系数则为+1或-1。基本语法:1
2
3
4spearman [varlist] [if] [in] [, spearman_options]
sysuse auto
spearman mpg rep78偏相关系数
偏相关系数类似于多元线性回归。当研究某一种因素对另一种因素的影响或相关程度,把其他因素的影响排除在外,而单独研究这两种因素之间的相关系数时,就要使用偏相关分析方法。
偏相关程度用片相关系数来衡量。即当有多个变量存在时,为了研究任意两个变量之间的关系,而使与这两个变量有联系的其他变量都保持不变,即控制其他变量,计算这两个变量之间的相关性。使用
pcorr可以计算偏相关系数,基本语法:1
2
3
4pcorr varname1 varlist [if] [in] [weight]
webuse wage
pcorr wage tenure hour age
1.1.7 数据分布
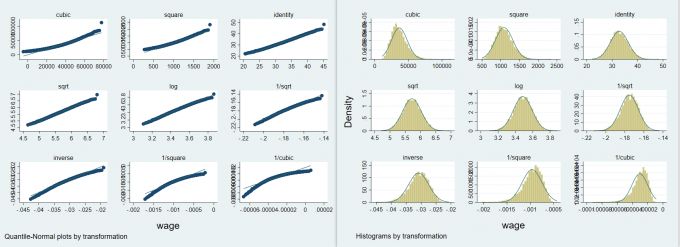
如果一个变量不符合正态分布可以考虑对数据进行非线性变换,常用的转换包括平方、三次方、自然对数等。Stata
提供了一个非常强大的工具 “幂阶梯” (ladder of powers)
可以尝试转换,然后依次进行偏度-峰度检验。主要的转换包括立方、平方、原始、平方根、对数等。基本命令:
1 | ladder varname [if] [in] |
Result:

此外,还可以通过 qladder 和 gladder
分别制作直方图和分位正态图。
1 | webuse wage |
Result:
1.2 Operations
1.2.1 Relational symbols
==: Equal;!=: Not equal;
1.2.2 Mathematical operation
数学运算,命令格式:
1 | display expression |
1.2.3 Logical operation
!: not&: and|: or
Example:
1 | sysuse auto, Clear |
1.3 Function
1.3.1 in 函数
in函数简介in用于指定观测值,可以是某一个观测值,也可以是某个区间的观测值。比如从第 10 个到 20 个观测值,基本语法如下:1
2
3
4
5command in range
sysuse auto, clear
list price in 300/500
list price in 10/l //last其中,
command是命令,range是从某个数到另外一个数
1.3.2 if 函数
if
函数用于一个命令后,用来满足表达式的数据集,基本语法:
1 | command if expression |
其中,command 代表某个 stata 命令,exp
是需要满足的表达式,表达式可以利用不同的运算符连接起来变量。
1.3.3 by 语句
Stata 语句大部分都允许使用 by
前置语句,用来对某些变量具有相同赋值的样本子集重复执行命令,by
语句的语法:
1 | by varlist: stata_cmd |
Result:
其中,stata_cmd 表示要执行的命令,by 和
bysort 的命令区别是是否对变量进行排序。
1.3.4 generate variables
generate 用于创建一个新变量,命令格式:
1 | generate [type] newva = exp [if] [in] |
1.3.5 real 函数简介
real
函数用于从合适的字符串表达式中得到数值,所以这个函数的定义域是各种字符串,而值域是数字和缺失值。命令格式:
1 | real(expression) = result |
1.4 Variables
1.4.2 Dummy variable
虚拟变量是最常见的指示指标,通常通过一个连续的变量进行转换可得。最简单的类别变量是取值为 0 和 1 的虚拟变量。生成虚拟变量的方法有两种。
- 利用
generate和replace命令组合生成虚拟变量,基本语法:
1
2gen college = 0 // 生成一个常数变量,赋值为 0
replace college = 1 if educ >= 12
- 使用
generate newvar命令生成虚拟变量。基本语法:
1
generate college = (educ >= 12) // 等同于上两个语句
1.4.3 Classified variables
生成分类变量可以使用很多方法,常用的命令有 generate 和
replace 命令组合,tabulate 命令以及
recode 命令,还可以使用
autocode(), recode(), group() 3 个函数。基本语法:
1 | recoded varlist (rule) [(rule)...] [, generate(newvar)] |
2 Drawing operation
2.1 绘图简介
Stata 的制图引擎提供了一整套制图工具与选项。不同目的、不同水平的用户都可以自由地选择自己需要的制图工具。如绘制二维散点图:
1 | graph twoway scatter var1 var2 |
图形的组成可以分为四部分:
- 由横轴和纵轴围成的图行的核心部分;
- 核心部分中诸如轴线间隔、连线、数值显示等附件部分;
- 用户在核心部分周围添加的诸如图形名称、轴线说明、图例名称、数据来源等文字;
- 在复杂图形中,用户添加在黑犀牛部分上的其他图行的叠加部分。
2.2 scatter plot
2.2.1 散点图简介
当用户面对的是两个连续变量时,散点图可以直观将数据呈现。散点图在探索变量的关系,为进一步的统计分级做准备工作中得到较为广泛的运用。基本语法:
1 | [twoway] scatter varlist [if] [in] [weight] [, options] |
如果命令后紧跟两个变量名,Stata 会默认第一个变量为 y
轴变量, 第二个为 x
轴变量。如果命令后跟着两个以上的变量,Stata 会将除最后一个以外的变量作为
y 轴变量,最后一个作为 x 轴变量。
| options | description |
|---|---|
| marker_options | change markers' look (color, size, etc.) |
| marker_label_options | add marker labels; change look, position |
| connect_options | change look of lines or connecting method |
| composite_style_option | overall style of the plot |
| jitter_options | jitter marker positions using random noise |
| axis_choice_options | associate plost with alternate axis |
| twoway_options | titles, legends, axes, aspect ratio, etc. |
2.2.2 散点设定
marker_options
散点显示选项的设定主要包括三点的形状、颜色、大小等。散点的形状
msymbol(symbolstylelist)、散点的颜色
mcolor(colorstylelist) 和三点的大小
msize(markersizestylelist) 等。
具体设定包含如下5个方面:
- 散点的形状
symbol; - 散点的大小
markersize; - 整体颜色;
- 内部的填充颜色
- 外保险的形状、厚度和颜色。
| marker_options | Description |
|---|---|
msymbol (m) |
shape of marker |
mcolor (mc) |
color and opacity of marker, inside and out |
msize (msiz) |
size of marker |
msangle (msa) |
angle of marker symbol |
mfcolor (mfc) |
inside or "fill" color and opacity |
mlcolor (mlc) |
color and opacity of outline |
mlwidth (mlw) |
thickness of outline |
mlalign (mla) |
outline alignment (inside, outside, center) |
mlstyle (mls) |
overall style of outline |
mstyle (msty) |
overall style of marker |
2.2.3 标签设定
marker_label_options
散点标签选项 marker_label_options
用于设定散点图标签(位于每个散点旁的用于说明散点所代表个体的文字),常见的选项由:
mlabel(varname):用于设定标签变量;mlabstyle(markerlabelstyle):用于设定标签的整体样式,包括:标签的位置、大小、方向等,取值在p1-p15之间。mlabposition(clockposstyle)、mlabvposition(varname):用于设定标签的位置,它们之间是可以相互替代的,前者设定一个常数应用到所有的点,后者设定一个变量指示每个变量的标签的方向,这个变量的取值在 0~12 之间。
| marker_label_options | Description |
|---|---|
| mlabel | specify marker variables |
mlabposition (mlabp) |
where to locate label |
mlabvposition (mlabv) |
where to locate label 2 |
mlabgap (mlabg) |
gap between marker and label |
mlabangle (mlabang) |
angle of label |
mlabsize (mlabs) |
size of label |
mlabcolor (mlabc) |
color and opacity of label |
mlabtextstyle (mlabt) |
overall style of text |
mlabstyle (mlabsty) |
overall style of label |
2.2.4 连线选项
connect_options
散点图的连线设置。
| connect_options | Description |
|---|---|
connect (c) |
how to connect points |
| sort | how to order data before connecting |
cmissing (cmis) |
missing values are ignored |
lpattern (l) |
line pattern (solid, dashed, etc.) |
lwidth (lw) |
thickness of line |
lcolor (lc) |
color and opacity of line |
lalign (la) |
line alignment (inside, outside, center) |
lstyle (lsty) |
overall style of line |
connect
1
2
3
4
5
6
7
8connectstyle Synonym Description
---------------------------------------------------------------
none i do not connect
direct l connect with straight lines
ascending L direct, but only if x[j+1] > x[j]
stairstep J flat, then vertical
stepstair vertical, then flat
---------------------------------------------------------------
2.2.5 振荡选项
jitter_options
有时候,由于数据点太密集,甚至产生了重叠,使得在观察数据中的趋势时受到影响。这时,需要将这些数据点轻微地挪动位置,使得重合的数据点相互分开,在
Stata 中振荡选项 jitter_options
就是用来达到振荡数据点的目的的。一旦设定了振荡选项
jitter(#),scatter
会在绘图前向数据中增加白噪声,选项中的 #
用来指定一个数字,表明振荡的程度占绘图区域的百分比。基本命令:
1 | scatter mpg weight, jitter(8) |
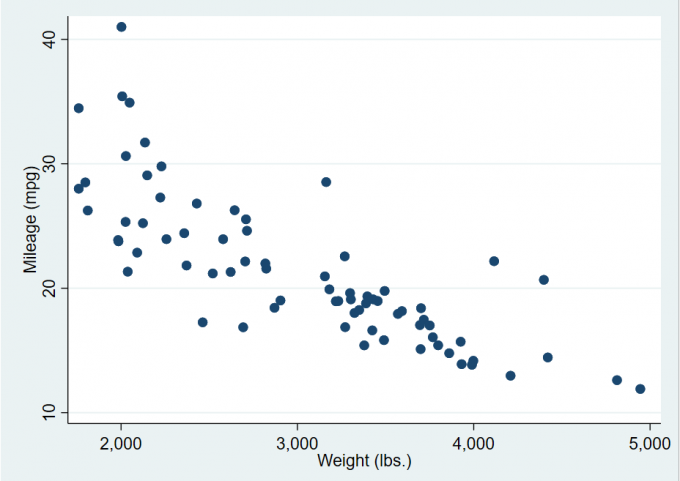
2.2.6 坐标选项
axis_choice_options
坐标选项 axis_options。主要包括:
axis_title_options;axis_label_options;axis_scale_options;axis_choice_options;axis_title_options
坐标轴标题选项组 axis_title_options
用于设定坐标轴的标题,主要包括:
ytitle(axis_title);xtitle(axis_title);ttitle(axis_title);ztitle(axis_title);
1
2scatter mpg price, ytitle("YYY") xtitle("XXX") // note: ' != "
scatter mpg price, ytitle("111YYY" "222YYY2") xtitle("111XXX" "222XXX" "333XXX")
axis_label_options
坐标轴刻度选项组 axis_label_options
主要用于控制坐标轴的刻度和刻度的标识。主要包括:
1
2
3
4
5
6
7axis_label_options Description
-------------------------------------------------------
{y|x|t|z}label(rule_or_values) major ticks plus labels
{y|x|t|z}tick(rule_or_values) major ticks only
{y|x|t|z}mlabel(rule_or_values) minor ticks plus labels
{y|x|t|z}mtick(rule_or_values) minor ticks only
-------------------------------------------------------
rule的设定;1
2
3
4
5
6
7
8
9
10rule Example Description
-------------------------------------------------------
## #6 approximately 6 nice values
### ##10 10-1=9 values between major ticks;
allowed with mlabel() and mtick() only
#(#)# -4(.5)3 specified range: -4 to 3 in steps of .5
minmax minmax minimum and maximum values
none none label no values
. . skip the rule
-------------------------------------------------------rules和numlists的设定;子选项
valuelable的使用;alternate选项的设定;grid和nogrid选项的设定。
1
2
3
4webuse auto
scatter mpg weight, ylabel(#5) xlabel(#5)
scatter mpg weight, ylabel(10(5)45) xlabel(1500 2000 3000 4000 4500 5000)
scatter mpg weight, ymtick(#20, grid) xmtick(#20, grid gmax)
axis_scale_option
坐标量度选项
axis_scale_option,用于对坐标轴进行量度科刻画。
1
2
3
4
5
6webuse auto
generate ln_weight = log(weight)
scatter mpg ln_weight
scatter mpg weight, xscale(log)
axis_choice_options
坐标尺度选项组
axis_choice_options,尺度选项的主要功能在于决定坐标轴时采用正常的算术刻度、对数刻度还是反方向刻度,坐标轴的数值范围以及坐标线的显示。主要包括设定
y 轴的外观、x 轴的外观和设定 t
轴的外观。在设定的同时,还可以设定子选项的外观。
2.2.7 twoway_options
主要包含如下信息:
| twoway_options | Description |
|---|---|
| added_line_options | draw lines at specified y or x values |
| added_text_options | display text at specified (y,x) value |
| axis_options | labels, ticks, grids, log scales |
| title_options | titles, subtitles, notes, captions |
| legend_options | legend explaining what means what |
| scale(#) | resize text and markers |
| region_options | outlining, shading, aspect ratio |
| aspect_option | constrain aspect ratio of plot region |
| scheme(schemename) | overall look |
| play(recordingname) | play edits from recordingname |
| by(varlist, ...) | repeat for subgroups |
| nodraw | suppress display of graph |
| name(name, ...) | specify name for graph |
| saving(filename, ...) | save graph in file |
| advanced_options | difficult to explain |
added_line_options增加线选项
added_line_options用于在二维图形上添加增加先,主要包括增加水平线,垂直线和特定的t轴上增加垂直线。基本语法:1
2
3
4
5
6xline(linearing), yline(linearing), tline(linearing)
// 其中 linearing 表示:numlist [, suboptions]
sysuse auto
scatter mpg price, yline(10)
scatter mpg price, yline(10, lstyle(foreground))Result:
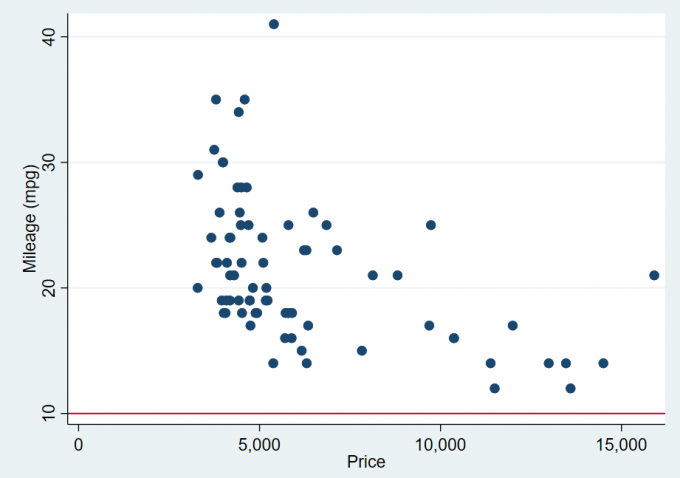
Fig.2-2 added_line_options
其中,
suboptions可以设定增加线的总样式、增加线的样式、增加线的粗细和增加线的颜色。axis_options轴选项包括:
axis_title_options;轴线选择项
yaxis(# [# ...])和xaxis(# [# ...])用来设定使用的是哪一个坐标,其中#取值为1到9,默认设置是yaxis(1)和xaxis(1),最常用的是对于y轴的选择,第一个y轴出现在图形的左侧,第二个y轴出现在图形的优策,而设定yaxis(12)将允许用户拥有两个相同的轴线。1
2
3
4
5twoway(scatter mpg weight)(scatter price weight, yaxis(2))
// 二维图,等价于:
scatter mpg weight || scatter price weight, yaxis(2)
scatter mpg weight || scatter price weight, yaxis(2) || , xlabel(#10) ytick(#10, axis(2)) ylabel(#8, axis(1))Result:
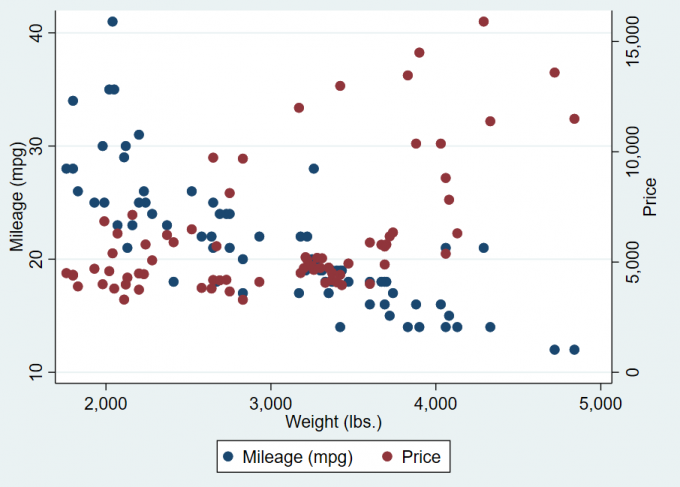
Fig. 2-3 Example of pie figure
axis_label_options;axis_scale_options;axis_choice_options。
legend_options当图形中包含多个组别的相似的内容时,
Stata将会生成图例。图例表示图形当中的不同符号对应着的内容,它使得读者能够轻松地读懂图中不同符号的含义。基本语法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19legend([contents] [location])
sysuse uslifeexp
line le year
line le_m le_f year // default legend
line le year, legend(on)
line le_m le_f year, legend(off)
label var le_m "Males"
label var le_f "Females"
line le_m le_f year
line le_m le_f year, legend(label(1 "Males") label(2 "Females"))
scatter le_m le_f year, c(l)legend(label(1 "Males") label(2 "Females"))
// c(l): 表示实现连线 connect(line)
scatter le_m le_f year, c(l)legend(pos(5) ring(0) col(1) label(1 "Males") label(2 "Females"))
// pos指时钟方位,ring(0) 表示离画图区域位置的距离。col指colsscale(#)scale(#)选项设定一个数字以便调整整个图像包括文本、标记和线段的大小,可这个选项实际上是整个图形的放大镜或者缩小镜。scale(1):默认设置,表示不改变图像大小;scale(1.2):使整个图像增大20%可以设置;scake(.8):为了使整个图像减少 20%,可以设置 。
1
2sysuse lifeexp
scatter lexp lgnp, scale(1.3)by_options设定选项
by()后,Stata会根据变量中的不同取值重复作图,因此by的依据往往是分类变量,比如性别、民族、国内国外等。基本语法:1
2by(varlist [, byopts])
// 其中,varlist是作图的根据变量,byopts是子选项关于by选项的设定- 选项
total表示除了对每一个组别分别作图外,还要添加一个含有全部样本的图行; 2) 选项row(#)和cols(#)是相互替代的,指设定所有图行共排列#行或列。
1
2
3
4
5use auto
scatter mpg weight, by(foreign)
scatter mpg weight, by(foreign, total)
scatter mpg weight, by(foreign, total row(1))
scatter mpg weight, by(foreign, total title("test"))Result:
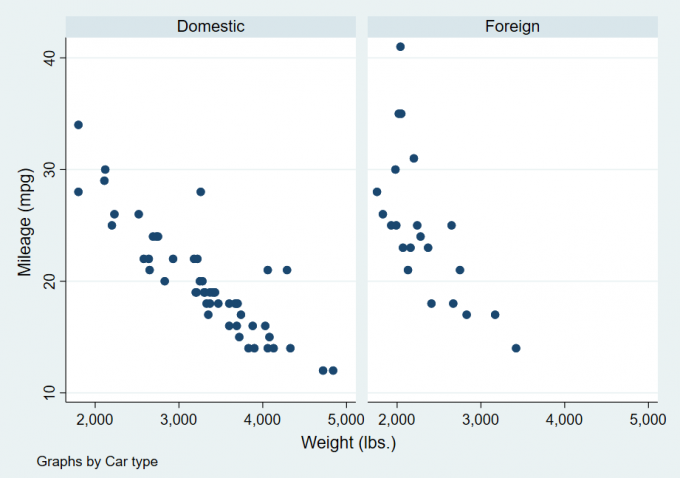
Fig.2-4 by_options
- 选项
save_options图形保存选项:
与处理数据文件一样,
Stata将本身生成的图形存储分为两种形式:一种是内存中的激活状态,另一种是存入硬盘的状态。在用户把当前文件存入硬盘之前,用户所绘制的图形均在内存中。用户可以选择是清楚或者存储,如果用户绘制另外一个图形,则自动清除之前保留在内存中的图形。基本语法:图形输出选项:1
2graph describe
graph save myfile, replace为了使生成的图形与其他设备或者图形、文字处理软件相连接,
Stata还提供了图形输出的工具,包括将图形输出到打印设备上和将图形输出成为其他格式的文件。主要包括:- 图形的打印
graph print; - 存储为其他格式
graph export newfilename.suffix。
- 图形的打印
2.2.8 点图
点图是一种散点图,其值在垂直方向上组合在一起(如直方图中的"合并"),而绘制的点在水平方向上分开。目的是在一个紧凑的图形中显示几个变量或组的所有数据。基本语法:
1 | dotplot varlist [if] [in] [, options] |
2.2.9 标绘图
曲线标绘图
曲线标绘图,就是其中的点用线段连接起来的散点图,和散点图一样,曲线标绘图的不同类型也属于
Stata功能强大的graph twoway族命令。散点图中控制添加坐标轴标签和标识的选项对曲线标绘图也起作用,新的选项可以控制曲线本身的特征。与散点图相比,曲线标绘图往往有不同的用法,如绘制描述随时间变化的变量。
1
2
3
4
5
6
7[twoway] line varlist [if] [in] [,options]
sysuse uslifeexp
graph twoway line le year
// twoway line le year
// line le year
scatter le year, msymbol(none) connect(l)Result:
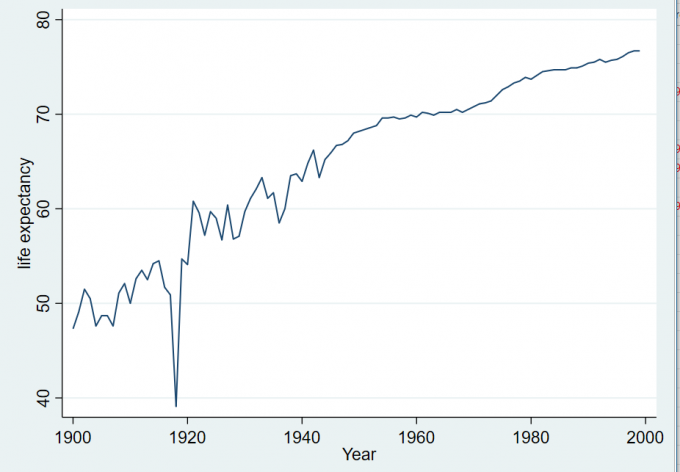
Fig.2-5 曲线标绘图
连线标绘图
在曲线标绘图中,数据点是看不见的,只能看到连线,使用连线标绘图可以把图中的数据点加以标记。基本命令:
1
2
3
4
5twoway connected varlist [if] [in] [weight] [, scatter_options]
sysuse uslifeexp
twoway connected le year
scatter le year, connect(l)Result:
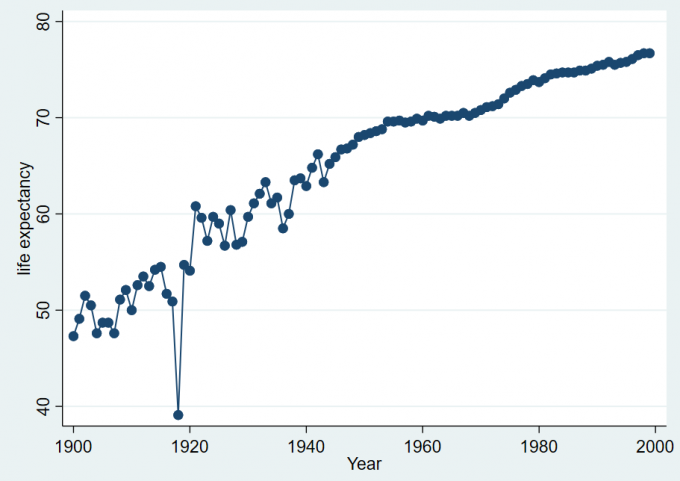
Fig. 2-6 连线标绘图
2.2.10 拟合图
一次拟合图形
一次拟合图形的绘制分两步:首先
Stata使用yvar为因变量,xvar为自变量进行一元线性回归,然后得到yvar的拟合值。比如说是hat,然后使用hat对xvar做曲线标绘图,同时复合原始数据的散点。基本语法:1
2
3
4
5
6
7
8twoway lfit yvar xvar [if] [in] [weight] [, options]
sysuse auto
scatter mpg weight || lfit mpg weight
// 等价于下述
regress mpg weight
predict fitted
scatter mpg weight || line fitter weight二次拟合图形
二次拟合图形的绘制分两步:首先
Stata使用yvar为因变量,xvar和xvar的平方为自变量进行二元线性回归,得到yvar的拟合值如取名为hat,然后使用hat对xvar做曲线标绘图,同时复合原始数据的散点图。基本语法:1
2
3
4
5
6
7
8
9twoway qfit yvar xvar [if] [in] [weight] [, options]
sysuse auto
scatter mpg weight || lfit mpg weight
// 原理类似于下述
generate tempvar = weight^2
regress mpg weight tempvar
predict fitted
scatter mpg weight || line fitted weightlowess拟合图形命令
lowess和graph twoway lowess皆可实现一种被称作 "lowess修匀" 的非参数拟合图的绘制。由于具有可对拟合过程进行控制的选项,lowess命令总的来说更为专业也更为强大。基本语法:1
2
3
4
5twoway lowess yvar xvar [if] [in] [, options]
sysuse auto
scatter mpg weight || lfit mpg weight || lowess mpg weight
scatter mpg weight || lfit mpg weight || lowess mpg weight||, by(foreign)
2.3 饼图
2.3.1 简介
基本语法:
1 | graph pie varname [if] [in] [weight], over(varname) [options] |
Result: 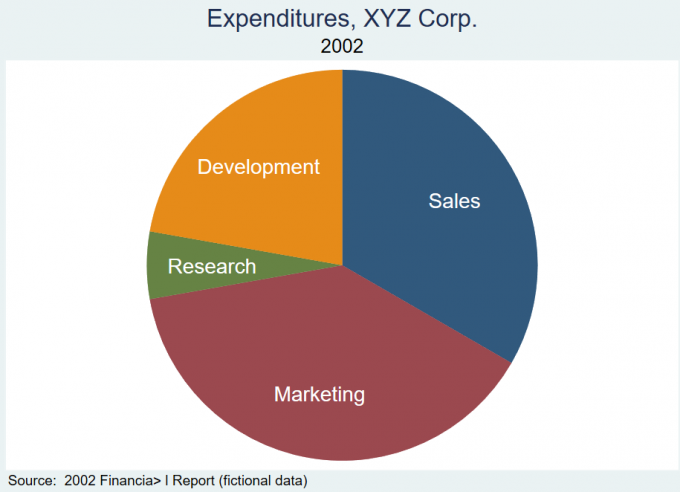
2.4 条形图
2.4.1 简介
条形图显示较为直观,可以显示众多的描述性统计量,同一个条形图中可以显示多个变量的统计量,比如均值、中位数、和、计数、标准差、最大值。基本语法:
1 | graph bar yvar [if] [in] [weight] [, options] // 纵向 |
3 Sample related
3.1 列联表 table
table
命令可以用于生成一维到多维的列联表,表中不仅可以包含常见的频数,还可以包含任意其他变量的描述性统计量。基本语法:
1 | table rowvar [colvar [supercolvar]] [if] [in] [weight] [, options] |
Result:

3.2 列联表 tabulate
tabulate
命令主要用于生成一维或者二维的表格,对于二维表格还可以进行独立性检验。tabulate
的一维命令主要用于生成含有频数的一维表格。二维 tabulate
命令在生成二维表格的同时,可以计算多种独立性检验统计量和相关测量统计量,包括常用的
Pearson's chi-squared、likelihood-ratio chi-squared、Cram's V、Fisher's exact test、Goodman and Kruskal's gamma、
Kendall's tau-b。基本语法:
1 | tabulate varlist [if] [in] [weight] [, tab1_options] |
3.3 样本 t 检验
3.3.1 单样本 t 检验
单样本检验的目的是比较样本均数所代表的未知总体均数 \mu 和已知总体均数 \mu_0 是否相等。其千题假设有散点:1) 已知一个总体均数;2) 可得到一个样本均数及该样本标准误;3) 样本来自正态或近似正态总体。计算公式为:
t = \frac{\bar{X} - \mu_0}{s/\sqrt{n}}
单样本检验步骤: 1. 建立假设,确定检验水准; 2. 计算统计量; 3. 确定 p 值,得出结论。
基本语法:
1 | ttest varname == # [if] [in] [, level] |
Result:

3.3.2 多样本 t 检验
多样本 t
检验分为两个正态总体的方差检验和两个正态总体的均值检验。基本语法:
两个正态总体的方差检验:
1
2
3
4
5sdtest varname1 == varname2 [if] [in], [, level(#)]
sdtest varname [if] [in], by(groupvar) [level(#)] // 借助分组
webuse fuel
sdtest mpg1 == mpg2Result:
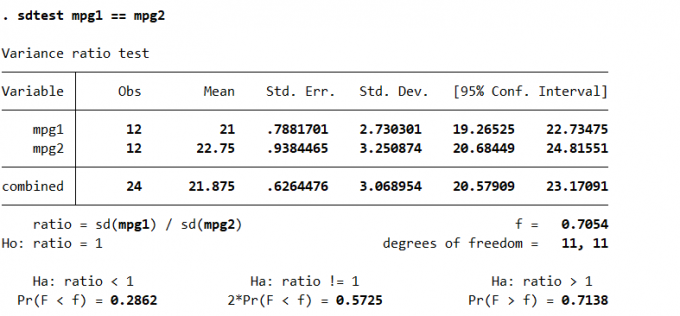
Fig. 两个样本的方差检验
其中,
P值未落入拒绝域,即表明两个方差默认相同。两个正态总体的均值检验:
1
2
3
4
5ttest varname1 == varname2 [if] [in] ,[, level(#)]
ttest varname [if] [in], by(groupvar) [option] // 借助分组
webuse fuel3
ttest mpg, by(treated)Result:
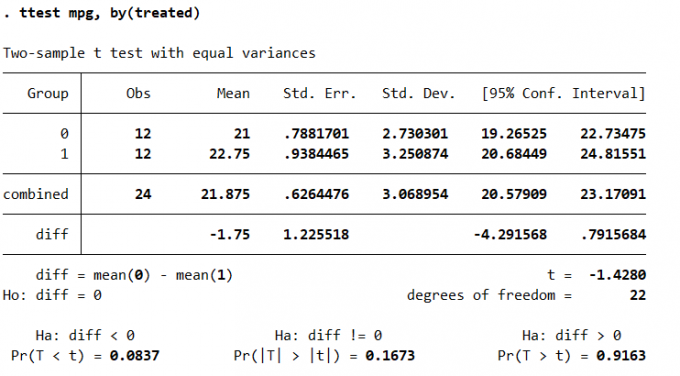
Fig. 两个样本的 t 检验
3.4 方差分析
3.4.1 单因素方差分析
单因素方差分析是指对单因素试验结果进行分析,检验因素对实验结果有无显著性影响的方法。单因素方差分析是两个样本平均数比较的引伸,它是用来检验多个平均数之间的差异,从而确定因素对实验结果有无显著性影响的一种统计方法。
单因素方差分析相关概念:1) 因素:影响研究对象的某一指标、变量。2) 水平:因素变化的各种状态或因素变化所分的等级或组别。3) 单因素实验:考虑的因素只有一个的试验叫单因素试验。基本命令:
1 | oneway response_var factor_var [if] [in] [weight] [, options] |
Result:
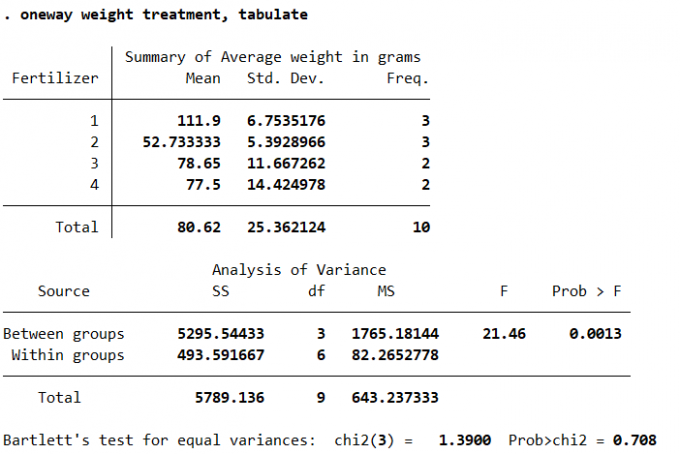
3.4.2 多因素方差分析
多因素方差分析法是一种统计分析方法,可以用来分析两个因素的不同水平对结果是否有显著影响。以及两因素之间是否存在交互效应。一般运用双因素方差分析法,先对两个因素的不同水平的组合进行设计试验,要求每个组合下所得到的样本的含量是相同的。基本语法:
1 | anova varname [termlist] [if] [in] [weight] [, options] |
Result:
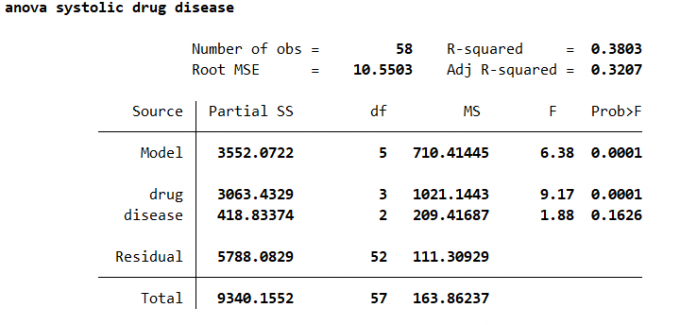
3.4.3 协方差分析
协方差分析将人为很难控制的控制因素作为协变量,并在排除协变量对观测变量影响的条件下,分析控制变量(可控)对观测变量的作用,从而更加准确地对控制因素进行评价。
协方差分析拓展了多因素方差分析,使之可以包含分类变量和连续变量的情况。当出现连续变量时,定义此变量,方差分析便可进行。基本语法:
1 | anova varname [termlist] [if] [in] [weight] c.(varlist) [, options] |
Result:
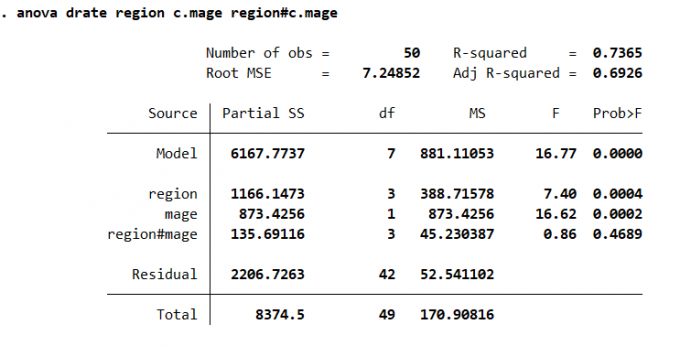
3.4.4 重复测量方差分析
在某些实验研究中,常常需要考虑时间因素对实验的影响,当需要对同一观察单位在不同时间重复进行多次测量,每个样本的测量数据之间存在相关性,因而不能简单地使用方差分析进行研究,而需要使用重复测量方差分析。基本语法:
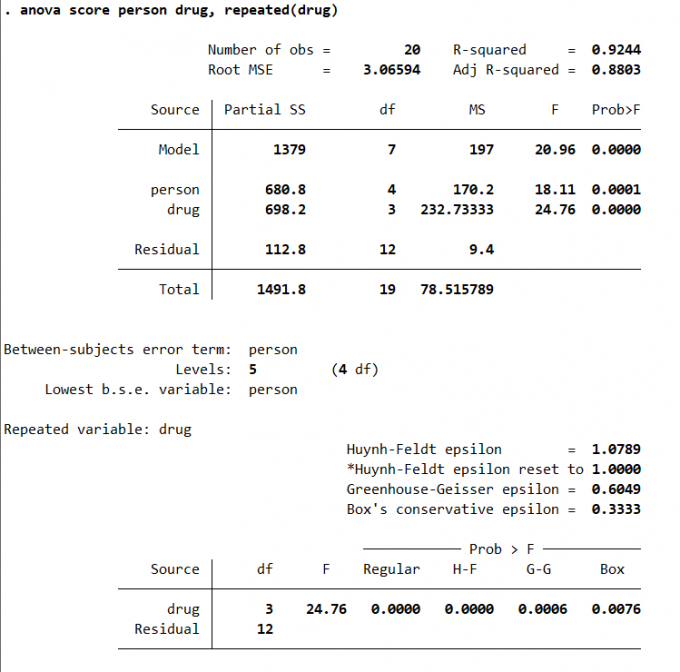
1 | anova varname [if] [in] [weight] [, repeated(varname)] |
Result:
3.5 假设检验
3.5.1 单个总体的假设检验分析
单个总体的假设检验时利用某些检验统计量,对样本的均值方差进行检验。主要分为三种:一直方差、未知方差、未知期望。基本命令:
1 | input kdqd |
正态分布,方差已知的均值检验
1
2
3
4
5quietly summarize
scalar z = (r(mean) - 32.5)/(1.1/sqrt(6)) // z 检验
scalar cri = invnormal(1-0.05/2) // 95% 置信度水平的临界值
scalar p = (1-normal(abs(z)))/2 // p 值
scalar list z cri pResult:

Fig. 方差已知的均值检验
正态分布,方差未知的均值检验
1
2
3ttest varname == # [if] [in] [, level(#)] // 正态分布,方差未知的均值检验
ttest kdqd == 32.5Result:
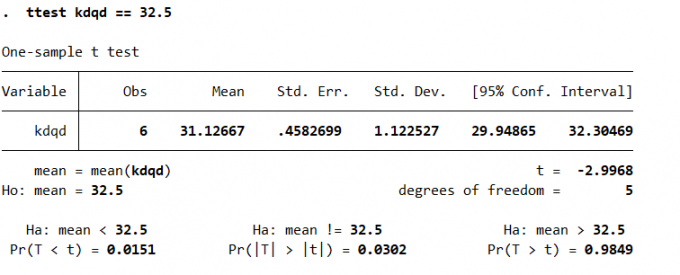
Fig. 方差未知的均值检验
期望未知检验方差
1
2
3sdtest varname == # [if] [in] [, level(#)] // 期望未知检验方差。
sdtest kdqd == 1.1Result:
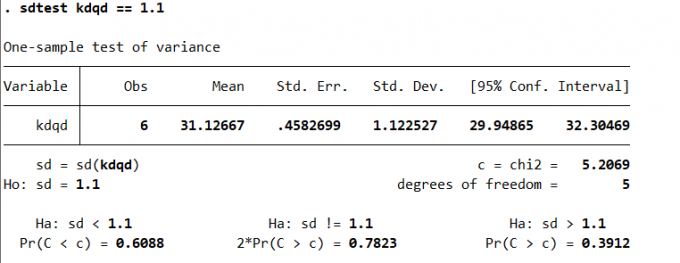
Fig. 期望未知的方差检验
3.5.2 两个总体的假设检验
在实际工作中,有时会用到两个正态总体的假设检验,两个正态中体的假设检验通常分为两种情况: 1. 均值(独立样本):z 检验(大样本)、t 检验(小样本)。
基本语法:
1
2
3ttest varname1 == varname2 [if] [in] [unequal, welch, level(#)]
ttest mpg1 == mpg2, unpaired // 非对称样本,数据并非针对同一个体
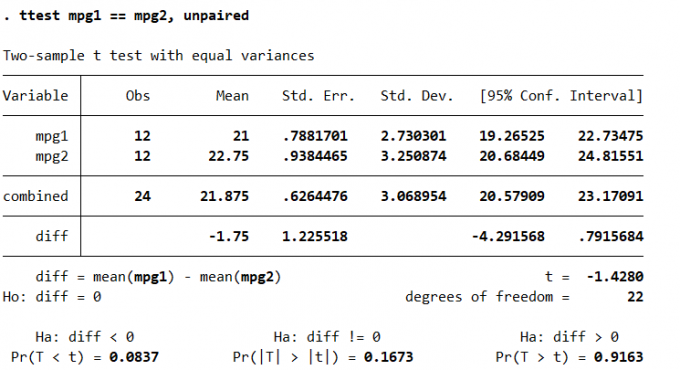
- 方差:F 检验。
1
2
3
4sdtest varname1 == varname2 [if] [in] [, level(#)]
webuse fuel
sdtest mpg1 == mpg2
3.6 最小二乘法分析
3.6.1 小样本的普通最小二乘分析
普通最小二乘估计方法 (Ordinary Least Square,简记为
OLS),是单一方程线性回归模型最常用、最基本的估计方法。OLS
的基本思想就是通过让残差 e
的平方和最小,从而使得模型的估计称为可能。基本命令:
1 | regress depvar [indepvar] [if] [in] [weight] [, options] |
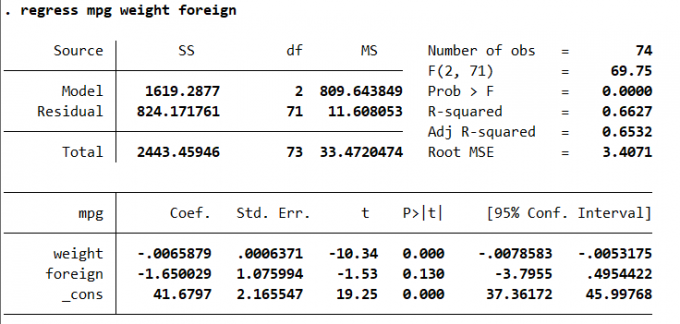
3.6.2 大样本的普通最小二乘分析
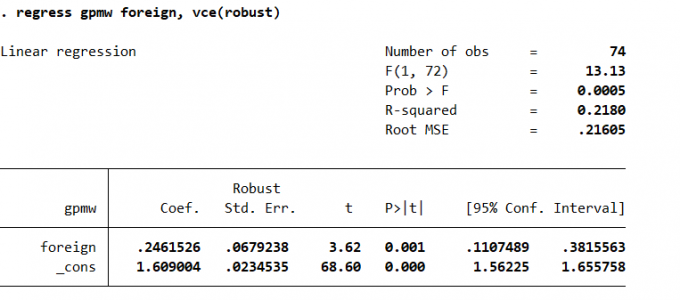
大样本普通最小二乘估计方法 (OLS)
适应性更强。在大样本下,只要研究其渐近分布就可以了,而渐近分布比较容易推到。大样本
OLS 经常采用稳健标准差估计 (robust)。
稳健标准差是指其标准差对于模型中可能存在的异方差或自相关问题不敏感,基于稳健标准差计算的稳健
t 统计量仍然渐近服从 t 分布。基本命令:
1 | regress depvar [indepvar] [if] [in] [weight] [, robust] |
Result:
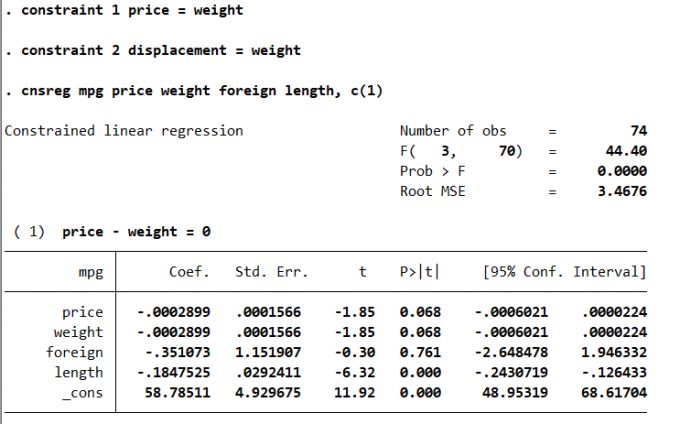
3.6.3 约束回归
在做回归分析时,有时会希望某些变量的系数相同或满足某种关系。约束回归通常可以通过对变量进行变换实现。
Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2
基本语法:
1 | constraint [define] # [exp = exp | coeflist] |
Result:
3.6.4 非线性最小二乘法
非线性最小二乘 (Nonlinear Least Square, NLS)
方法是一种以误差的平方和最小为准则来估计非线性静态模型参数的一种参数估计方法。通常情况下,非线性最小二乘方法没有解析解,一般使用数值方法求解。基本语法:
1 | nl (depvar = <sexp>) [if] [in] [weight] [, options] |
4. Model specification
4.1 Dummy variables
对于定性数据,通常不能将其直接纳入模型中进行回归分析。需要进行虚拟变量进行处理。一般情况下,如果分类变量总供有
N 类,为了避免多重共线性的出现,通常引入 N-1
个虚拟变量。基本语法:
1 | generate varname = value // 生成带初始值的虚拟变量 |
4.2 变量分组统计分析
statsby 是对变量分组 (bysort) 进行统计分析
(statstics)。基本语法:
1 | statsby [exp_list] [, options]: command |
Result:

4.3 遗漏变量
遗漏变量属于解释变量选取错误的一种。因为某些数据难以获取,有时未获得的数据会降低模型的精度。可以通过遗漏变量进行处理。Stata
提供两种遗漏变量检验方法:Link 检验和 Ramsey
检验。基本语法:
1 | linktest [if] [in] [, cmd_options] |
4.4 自变量熟练的选择
在统计模型的设计过程中,通常希望模型简介简单。通常使用信息准则来确定解释变量的个数。常见的信息准则有:
- 赤池信息准则
在衡量统计模型拟合优良性 (Gooodness of fit)
的一种标准。它建立在熵的概念基础上,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。
- 贝叶斯信息准则
是在不完全请报下,对部分未知的状态用主观概率估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最优决策
1
estatic [, n(#)]
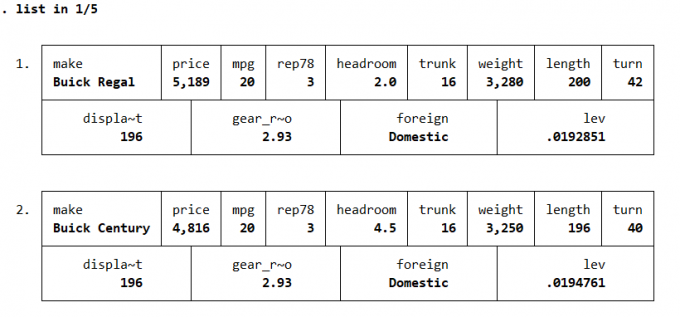
4.5 极端数据的诊断与处理
再全体观测值中,会有一些样本和总体样题距离较远,这些样本再回归中可能会对斜率或者截距的估计产生较大的影响。
在 Stata
中,如果解释变量过多或者是面板数据,绘图方式并不直观。通常使用
leverage 影响力方法判断该数据是否是极端数据。若数据的
leverage
影响力值高于平均值,则对回归系数影响较大,可能会产生极端数据的影响。
1 | sysuse auto |
Result:
4.6 多重共线性与逐步回归法
多重共线性 (陈强,P_{171})
多重共线性问题,在多元线性回归分析中很常见。非常容易导致方程回归系数估计的标准误差变大,系数估计值的精度降低等。多重共线性的通常症状时,虽然整个回归方程的 \mathcal{R}^2 较大、F 检验也很显著,但单个系数的 t 检验却不显著。
当确认模型存在多重共线性时,通常有两种解决方法来消除影响:1) 收集更多的数据,增大样本容量。2) 通过逐步分析回归改进模型的形式。
逐步回归法
逐步回归法的基本原理时分别拟合被解释变量,对于每一个解释变量的一元回归,并将各回归方程的拟合优度按照大小顺序排列,然后将拟合优度最大的解释变量作为基础变量,逐步将其他变量加入模型中,观测
t值的变化。1
stepwise [, options] : command
4.7 异方差检验与处理 (陈强,P_{132})
异方差,是指误差项 u
对不同的的个体是不同的,即条件方差 Var(\varepsilon_i | X) 依赖于 i,而不是常数 \sigma^2。
违反了球形误差的假设。异方差的检验通常有三种方法: 1.
较为直观地观察方法进行回归后画出残差图 ecdplot varname 2.
BP 检验 estat hettest, normal 3. 怀特检验
estat imtest, white
异方差的处理: 1. 稳健便准差 OLS 法 2. GLS
法(广义最小二乘法)
4.7 内生性 (陈强,P_{193})
OLS
能够成立的最重要条件是解释变量于扰动项不相关(同期外生性)。内生性指解释变量于扰动项相关。内生性通常来源于遗漏变量偏差、经典的测量误差问题和联立性(逆向因果)。如果出现内生性问题,通常解决办法是使用工具变量,利用二阶段最小二乘方法进行解决。基本语法:
1 | ivregress 2sls y [varlist 1] (varlist2 = instlist) [if] [in] [weight] [, option] |
4.8 二值选择模型
4.8.1 二值选择模型 (陈强,P_{212})
当被解释的变量可选值只有两个的时候,可以建立二值选择模型进行分析问题。Stata
二值选择模型主要有 Probit 和 Logit
模型。基本语法:
1 | logit depvar [indepvars] [if] [in] [weight] [, options] |
4.8.2 多指选择模型
当选择为多个且互相独立时,可以选用多值选择模型。比如,消费者选择不同品牌,旅游者选择不同的交通方式等。基本语法:
1 | mlogit depvar [indepvars] [if] [in] [weight] [, options] |
4.8.3 排序选择模型
在因变量不止两种选择时,就要用到多元选择模型。多元离散选择问题普遍存在于经济生活中。例如:一个人面临多重职业选择,将可共选择的职业排队,用0,1,2,3 表示。影响选择的因素有不同职业的收入、发展前景和个人偏好等。所谓“排序”是指在各个选项之间有一定的顺序或级别种类。基本语法:
1 | ologit depvar [indepvars] [if] [in] [weight] [, options] |
4.8.4 条件 Logit 模型
面临多个选择时,选择的依据是个体的特点。但有时,在模型选择过程中,个体选择受外部因素影响,此时可以选用条件
Logit
模型,模型可以解决解释变量中存在的选择特征问题。基本问题:
1 | clogit y x1 x2 [if] [in] [weight] , group(varname) [options] |
4.8.5 嵌套 Logit 模型
在进行模型选择的时候,很多个体的选择是分层次的,下面层次的选择受到上面层次的限制,相同层次之间的选择具有替代性,层次之间的选择又不相关。这时可以选择嵌套
Logit 模型进行处理。嵌套 Logit
模型的参数估计方法有两种:一种是两阶段最大似然法;另一种是完全信息最大似然法。基本语法:
1 | nlogitgen newvar = alvar(bracnchlist) [, nolog] |
4.9 主成分分析
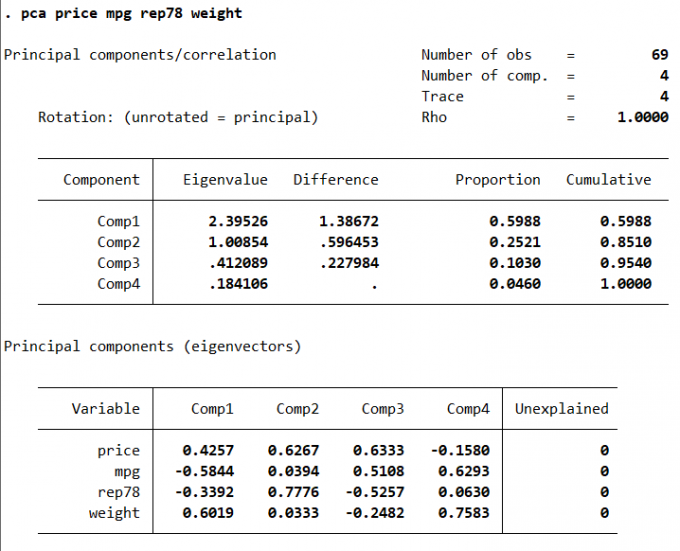
主成分分析是设法将原来众多具有一定相关性(比如 P 个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。在许多领域的研究与应用中,往往需要反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律。基本语法:
1 | pca varlist [if] [in] [weight] [, options] |
Result:
5 时间序列
5.1 时间序列的定义
时间序列分析方法通常适用于多种领域,包括经济、气象、过程控制等。通常依据变量自身的变化规律,利用外推机制描述时间序列的变化。在使用时间序列数据进行分析前,通常需要定义时间变量,通过新的观测值,或者需要对时间序列进行预测。基本语法:
1 | tsset timevar [, option] |
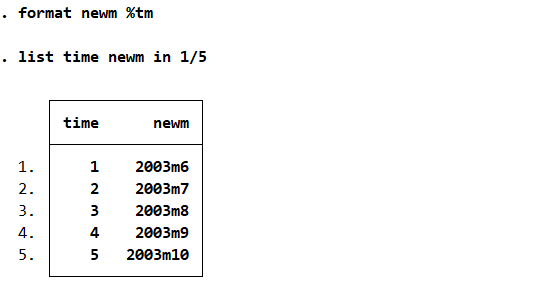
时间序列拓展
1
2
3
4webuse idle2
generate newm = tm(2003m6) + time - 1
tsset newm, monthly
tsappend, add(12) // 时间序列拓展
5.2 时间序列图与白噪声
时间序列的相关性代表了信息,自相关函数和偏自相关函数可以直观观测信息度。同时,可以采用
Q 统计量来检验白噪声。基本语法:
1 | corrgram varname [if] [in], [, corrgram_options] |
5.3 ARIMA 模型
5.3.1 ARIMA 模型
ARIMA
模型差分整合移动平均自回归模型,常用模型包括:自回归模型
(AR)、滑动平均模型
(MA)、自回归-滑动平均混合模型
(ARMA)、差分整合移动平均自回归莫i选哪个
(ARIMA)。基本语法:
1 | arima depvar [indepvars], ar(numlist) ma(numlist) |
5.3.2 SMARIMA 模型
在某些时间序列中,存在明显的周期变化。这种周期是由于季节性变化(包括季度、月度、周度变化)或其他一些固有因素引起的。这类序列称为季节性序列。经济领域中,季节性时间序列更为常见。如季度时间序列、月度时间序列、周度时间序列等。基本语法:
1 | arima depvar, arima(#p, #d, #q) sarima(#P, #D, #Q, #s) |
5.3.3 ARIMAX 模型
ARIMAX 模型,分别是名称 ARMA 和
ARIMA 的扩展,ARMAX 和
ARIMAX。添加到末尾 X
代表“外源”。它表示建议添加一个单独的不同外部变量以帮助测量内生变量。基本语法:
1 | arima depvar [indepvars] [if] [in] [weight] [, options] |
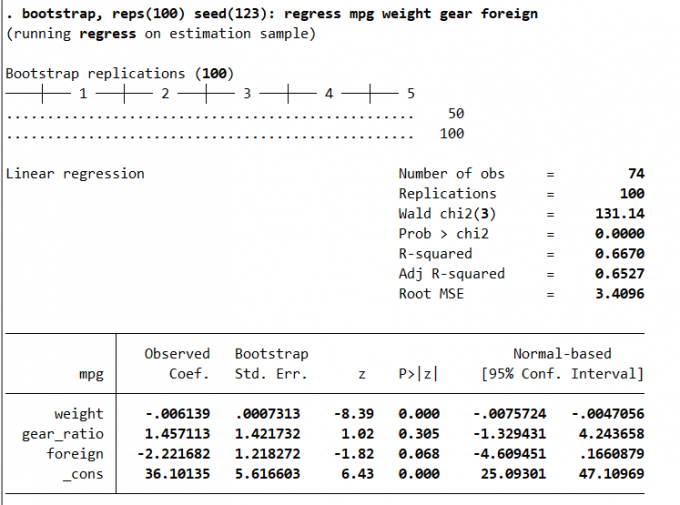
5.3 自助法
自助法 (Bootstrap)
是一种从给定训练样本集中有放回的均匀抽样。每当选中一个样本,它等可能地被再次选中并被再次添加到训练集中。自助法优点是不必对模型的数据生成过程做出假定。基本语法:
1 | bootstrap exp_list [, options eform_option] : command |
Result:
6 软件相关
6.1 do 文件
快捷键:ctrl + 9
6.2 注释
- 通过
*声明一行注释 - 通过
/*和*/进行注释 - 通过
//注释 - 通过
///注释
6.3 临时文件
1 | tempvar var1 var2 // 临时变量 |