1 2 3 4 5 6 7 8 9 s2 = 'It took me six months to write this Python tutorial. \ Please give me more support. \ I will keep it updated.' num = 20 + 3 / 4 + \ 2 * 3 print(num)
1 2 3 4 ''' Long string information '''
1 2 3 4 5 6 7 8 9 10 rstr = r'D:\Program Files\Python 3.8\python.exe' print(rstr) str2 = r'I\'m a great coder!' print(str1) str3 = r'D:\Program Files\Python 3.8' + '\\' print(str1)
Bytes 类型表示一个字节串,时Python 3 新增的, python 2 中不存在
Bytes 和 string 的对比:
string由若干个字符组成,以字符为单位进行操作;Bytes由字节组成
除了操作的处理单元不同,它们支持的所有方法基本相同
都是不可变序列,不能随意增加和删除数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 b1 = bytes () b2 = b'' b3 = b'http://c.biancheng.net/python/' print("b3: " , b3) print(b3[3 ]) print(b3[7 :22 ]) b4 = bytes ('C语言中文网8岁了' , encoding='UTF-8' ) print("b4: " , b4) b5 = "C语言中文网8岁了" .encode('UTF-8' ) print("b5: " , b5) str1 = b5.decode('UTF-8' ) print("str1: " , str1)
输出结果:
1 2 3 4 5 6 b3: b'http://c.biancheng.net/python/' 112 b'c.biancheng.net' b4: b'C\xe8\xaf\xad\xe8\xa8\x80\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x918\xe5\xb2\x81\xe4\xba\x86' b5: b'C\xe8\xaf\xad\xe8\xa8\x80\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x918\xe5\xb2\x81\xe4\xba\x86' str1: C语言中文网8 岁了
从运行结果可以发现,对于非 ASCII 字符,print 输出的是它的字符编码值(十六进制形式),而不是字符本身。非 ASCII 字符一般占用两个字节以上的内存,而 bytes 是按照单个字节来处理数据的,所以不能一次处理多个字节。
1 2 3 4 program = ["C语言" , "Python" , "Java" ] emptylist = [ ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 list1 = list ("hello" ) print(list1) tuple1 = ('Python' , 'Java' , 'C++' , 'JavaScript' ) list2 = list (tuple1) print(list2) dict1 = {'a' :100 , 'b' :42 , 'c' :9 } list3 = list (dict1) print(list3) range1 = range (1 , 6 ) list4 = list (range1) print(list4) print(list ())
运行结果:
1 2 3 4 5 ['h' , 'e' , 'l' , 'l' , 'o' ] ['Python' , 'Java' , 'C++' , 'JavaScript' ] ['a' , 'b' , 'c' ] [1 , 2 , 3 , 4 , 5 ] []
1 listname[start : end : step]
1 2 3 4 5 6 del listnamedel listname[index]del listname[start : end]
remove() 方法:根据元素本身的值来进行删除操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 nums = [40 , 36 , 89 , 2 , 36 , 100 , 7 ] nums.remove(36 ) print(nums) nums.remove(36 ) print(nums) nums.remove(78 ) print(nums)
运行结果
1 2 3 4 5 6 7 8 [40 , 89 , 2 , 36 , 100 , 7 ] [40 , 89 , 2 , 100 , 7 ] Traceback (most recent call last): File "D:\Demo\Python\Test\Test1.py" , line 493 , in <module> nums.remove(78 ) ValueError: list .remove(x): x not in list
1 2 3 4 url = list ("http://c.biancheng.net/python/" ) url.clear() print(url)
运行结果:
1 2 3 4 5 6 7 8 9 10 language = ["Python" , "C++" , "Java" ] birthday = [1991 , 1998 , 1995 ] info = language + birthday print("language =" , language) print("birthday =" , birthday) print("info =" , info) ''' + 运算符可以将多个修了连接起来,相当于在第一个列表的末尾添加了另一个列表 '''
1 2 listname.insert(index, obj)
1 2 3 4 nums = [40 , 36 , 89 , 2 , 36 , 100 , 7 ] nums[2 ] = -26 nums[-3 ] = -66.2 print(nums)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 nums = [40 , 36 , 89 , 2 , 36 , 100 , 7 ] nums[1 : 4 ] = [45.25 , -77 , -52.5 ] print(nums) · nums = [40 , 36 , 89 , 2 , 36 , 100 , 7 ] nums[4 : 4 ] = [-77 , -52.5 , 999 ] print(nums) nums = [40 , 36 , 89 , 2 , 36 , 100 , 7 ] nums[4 : 4 ] = -77 nums = [40 , 36 , 89 , 2 , 36 , 100 , 7 ] nums[1 : 6 : 2 ] = [0.025 , -99 , 20.5 ] print(nums)
1 2 3 4 5 6 7 8 9 10 11 listname.index(obj,start,end) nums = [40 , 36 , 89 , 2 , 36 , 100 , 7 , -20.5 , -999 ] print( nums.index(2 ) ) print( nums.index(100 , 3 , 7 ) ) print( nums.index(7 , 4 ) ) print( nums.index(55 ) )
count() 方法:统计某个元素在列表中出现的次数
1 tuplename = (element1, element2, ... )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 tuple (data)tup1 = tuple ("hello" ) print(tup1) list1 = ['Python' , 'Java' , 'C++' , 'JavaScript' ] tup2 = tuple (list1) print(tup2) dict1 = {'a' :100 , 'b' :42 , 'c' :9 } tup3 = tuple (dict1) print(tup3) range1 = range (1 , 6 ) tup4 = tuple (range1) print(tup4) print(tuple ())
运行结果
1 2 3 4 5 ('h' , 'e' , 'l' , 'l' , 'o' ) ('Python' , 'Java' , 'C++' , 'JavaScript' ) ('a' , 'b' , 'c' ) (1 , 2 , 3 , 4 , 5 ) ()
1 tuplename[start: end: step]
元组是不可变序列,元组中的元素不能被修改
1 2 3 4 5 6 7 8 tup = (100 , 0.5 , -36 , 73 ) print(tup) tup = ('Shell脚本' ,"http://c.biancheng.net/shell/" ) print(tup)
dict 是一种无序的、可变的序列,他的元素以“键值对(key - value)”的形式存储
Fig. 1-1 字典数据结构
1 2 dictname = {'key' :'value1' , 'key2' :'value2' , ..., 'keyn' :valuen}
1 2 3 4 5 6 dictname = dict .fromkeys(list , value = None ) knowledge = {'语文' , '数学' , '英语' } scores = dict .fromkeys(knowledge, 60 ) print(scores)
表1-1 dict() 函数创建字典
创建格式
注意事项
a = dict(str1=value1, str2=value2, str3=value3)
str 表示字符串类型的键,value 表示键对应的值。使用此方式创建字典时,字符串不能带引号。
#方式1
向 dict() 函数传入列表或元组,而它们中的元素又各自是包含 2 个元素的列表或元组,其中第一个元素作为键,第二个元素作为值。
keys = [‘one’, ‘two’, ‘three’]
通过应用 dict() 函数和 zip() 函数,可将前两个列表转换为对应的字典。
如果不为 dict() 函数传入任何参数,则表示创建空字典
1 2 3 4 5 6 7 dictname[key] tup = (['two' ,26 ], ['one' ,88 ], ['three' ,100 ], ['four' ,-59 ]) dic = dict (tup) print(dic['one' ]) print(dic['five' ])
运行结果
1 2 3 4 5 88 Traceback (most recent call last): File "C:\Users\mozhiyan\Desktop\demo.py" , line 4 , in <module> print(dic['five' ]) KeyError: 'five'
1 2 3 4 5 6 dictname.get(key[,default]) a = dict (two=0.65 , one=88 , three=100 , four=-59 ) print( a.get('one' ) ) print( a.get('five' , '该键不存在' ) )
运行结果
1 2 dictname[key] = new value
判断字典中是否存在指定键值对( in 或 not in 运算符)
1 2 3 4 5 a = {'数学' : 95 , '语文' : 89 , '英语' : 90 } print('数学' in a) print('物理' in a)
运行结果
1 2 3 4 scores = {'数学' : 95 , '语文' : 89 , '英语' : 90 } print(scores.keys()) print(scores.values()) print(scores.items())
运行结果
1 2 3 4 dict_keys(['数学' , '语文' , '英语' ]) dict_values([95 , 89 , 90 ]) dict_items([('数学' , 95 ), ('语文' , 89 ), ('英语' , 90 )])
在 Python 2.x 中,上面三个方法的返回值都是列表(list)类型。但在 Python 3.x 中,它们的返回值并不是我们常见的列表或者元组类型,因为 Python 3.x 不希望用户直接操作这几个方法的返回值。
在 Python 3.x 中如果想使用这三个方法返回的数据,一般有下面两种方案:
使用 list() 函数,将他们转化为列表
1 2 3 a = {'数学' : 95 , '语文' : 89 , '英语' : 90 } b = list (a.keys()) print(b)
运行结果
使用 for in 循环遍历
1 2 3 4 5 6 7 8 9 a = {'数学' : 95 , '语文' : 89 , '英语' : 90 } for k in a.keys(): print(k,end=' ' ) print("\n---------------" ) for v in a.values(): print(v,end=' ' ) print("\n---------------" ) for k,v in a.items(): print("key:" ,k," value:" ,v)
运行结果
1 2 3 4 5 6 7 数学 语文 英语 --------------- 95 89 90 --------------- key: 数学 value: 95 key: 语文 value: 89 key: 英语 value: 90
update方法可以使用一个字典所包含的简直对来更新已有的字典。
在执行 update()方法是,如果被更新的字典中已包含对应的键值对,那么原 value会被覆盖;如果不包含对应的键值对,则该键值对被添加进去
1 2 3 a = {'one' : 1 , 'two' : 2 , 'three' : 3 } a.update({'one' :4.5 , 'four' : 9.3 }) print(a)
运行结果
1 {'one' : 4.5 , 'two' : 2 , 'three' : 3 , 'four' : 9.3 }
都是用来删除字典中键值对,不同的是,pop() 用来删除指定的键值对,而 popitem() 用来随机删除一个键值对
1 2 dictname.pop(key) dictname.popitem()
1 2 3 4 5 6 a = {'数学' : 95 , '语文' : 89 , '英语' : 90 , '化学' : 83 , '生物' : 98 , '物理' : 89 } print(a) a.pop('化学' ) print(a) a.popitem() print(a)
运行结果
1 2 3 {'数学' : 95 , '语文' : 89 , '英语' : 90 , '化学' : 83 , '生物' : 98 , '物理' : 89 } {'数学' : 95 , '语文' : 89 , '英语' : 90 , '生物' : 98 , '物理' : 89 } {'数学' : 95 , '语文' : 89 , '英语' : 90 , '生物' : 98 }
setdefault() 方法:返回某个 key 对应的 value
1 2 3 4 5 6 7 8 9 dictname.setdefault(key, defaultvalue) ''' 当指定的 key 不存在时,setdefault() 会先为这个不存在的 key 设置一个默认的 defaultvalue,然后再返回 defaultvalue 也就是说,setdefault() 方法总能返回指定 key 对应的 value: 1) 如果该 key 存在,那么直接返回该 key 对应的 value; 2) 如果该 key 不存在,那么先为该 key 设置默认的 defaultvalue,然后再返回该 key 对应的 defaultvalue。 '''
copy() 返回一个字典的拷贝,即一个具有相同键值对的新字典
1 2 3 4 5 6 7 a = {'one' : 1 , 'two' : 2 , 'three' : [1 ,2 ,3 ]} b = a.copy() print(b) ''' '''
运行结果
1 {'one' : 1 , 'two' : 2 , 'three' : [1 , 2 , 3 ]}
copy() 方法所遵循的拷贝原理,既有深拷贝,也有浅拷贝。
拿拷贝字典 a 为例,copy() 方法只会对最表层的键值对进行深拷贝,也就是说,它会再申请一块内存用来存放 {‘one’: 1, ‘two’: 2, ‘three’: []};而对于某些列表类型的值来说,此方法对其做的是浅拷贝,也就是说,b 中的 [1,2,3] 的值不是自己独有,而是和 a 共有。
1 2 3 4 5 6 7 8 9 10 11 12 a = {'one' : 1 , 'two' : 2 , 'three' : [1 ,2 ,3 ]} b = a.copy() a['four' ]=100 print(a) print(b) a['three' ].remove(1 ) print(a) print(b)
运行结果
1 2 3 4 {'one' : 1 , 'two' : 2 , 'three' : [1 , 2 , 3 ], 'four' : 100 } {'one' : 1 , 'two' : 2 , 'three' : [1 , 2 , 3 ]} {'one' : 1 , 'two' : 2 , 'three' : [2 , 3 ], 'four' : 100 } {'one' : 1 , 'two' : 2 , 'three' : [2 , 3 ]}
同一集合中,只能存储 不可变 的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变 的数据类型,否则会抛出 TypeError 错误。
1 2 {element1,element2,...,elementn}
1 setname = {element1,element2,...}
1 2 3 4 5 6 7 8 9 setname = set (iteration) set1 = set ("c.biancheng.net" ) set2 = set ([1 ,2 ,3 ,4 ,5 ]) set3 = set ((1 ,2 ,3 ,4 ,5 )) print("set1:" ,set1) print("set2:" ,set2) print("set3:" ,set3)
运行结果
1 2 3 set1: {'a' , 'g' , 'b' , 'c' , 'n' , 'h' , '.' , 't' , 'i' , 'e' } set2: {1 , 2 , 3 , 4 , 5 } set3: {1 , 2 , 3 , 4 , 5 }
1 2 3 a = {1 ,'c' ,1 ,(1 ,2 ,3 ),'c' } for ele in a: print(ele,end=' ' )
1 2 3 4 a = {1 ,'c' ,1 ,(1 ,2 ,3 ),'c' } print(a) del (a)print(a)
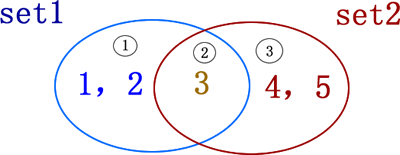
Fig. 1-2 集合的布尔运算
表 1-2 集合的布尔运算
运算操作
Python运算符
含义
例子
交集
&
取两集合公共的元素
>>> set1 & set2 {3}
并集
|
取两集合全部的元素
>>> set1 | set2 {1,2,3,4,5}
差集
-
取一个集合中另一集合没有的元素
>>> set1 - set2 {1,2}
对称差集
^
取集合 A 和 B 中不属于 A&B 的元素
>>> set1 ^ set2 {1,2,4,5}
set 集合方法详解
str 表示一个字符串类型的变量,input 会将读取到的字符串放入 str 中
tipmsg 表示提示信息,它会显示在控制台上,告诉用户应该输入什么样的内容;如果不写 tipmsg,就不会有任何提示信息
1 print(value,..., sep ='' , end = '\n' , file = sys.stdout, flush = False )
value 参数可以接受任意多个变量或值,如:
1 2 3 4 user_name = 'Charlie' user_age = 8 print("读者名:" ,user_name,"年龄:" ,user_age, sep = '|' )
1 2 3 4 5 6 str (obj)repr (obj)''' '''
str() 和 repr() 的区别
str() 和 repr() 函数虽然都可以将数字转换成字符串,但它们之间是有区别的:
str() 将数据转换成适合人类阅读的字符串形式
repr() 将数据转换成适合解释器阅读的字符串形式(Python 表达式的形式),适合在开发和调试阶段使用;如果没有等价的语法,则会发生 SyntaxError 异常。
1 2 3 4 5 6 7 s = "http://c.biancheng.net/shell/" s_str = str (s) s_repr = repr (s) print( type (s_str) ) print (s_str)print( type (s_repr) ) print (s_repr)
运行结果
1 2 3 4 <class 'str '> http :<class 'str '> 'http : //c.biancheng.net/shell/'
1 2 strname[index] strname[start : end : step]
图 2-1 UTF-8
1 2 3 4 5 6 str .split(sep,maxsplit)''' str: 表示要分割的字符串 sep: 用于指定分隔符,可以包含多个字符,默认为 None,表示所有空字符 maxsplit:可选参数,用于指定分割的次数,最后列表中子串的个数最多为 maxsplit+1。如果不指定或者指定为 -1,则表示分割次数没有限制。 '''
1 2 3 4 5 6 7 8 9 10 newstr = str .join(iterable) ''' newstr:表示合并后生成的新字符串; str:用于指定合并时的分隔符; iterable:做合并操作的源字符串数据,允许以列表、元组等形式提供。 ''' list = ['c' ,'biancheng' ,'net' ]'.' .join(list )
1 2 3 4 5 6 7 8 9 10 str .count(sub[,start[,end]])''' str:表示原字符串; sub:表示要检索的字符串; start:指定检索的起始位置,也就是从什么位置开始检测。如果不指定,默认从头开始检索; end:指定检索的终止位置,如果不指定,则表示一直检索到结尾。 ''' str = "c.biancheng.net" str .count('.' )
1 str .find(sub[,start[,end]])
1 2 str .index(sub[,start[,end]])
1 2 3 4 5 6 S.ljust(width[, fillchar]) ''' S:表示要进行填充的字符串; width:表示包括本身长度在内,字符串要占的总长度; fillchar:作为可选参数,用来指定填充字符串时所用的字符,默认情况使用空格。 '''
1 S.rjust(width[, fillchar])
1 S.center(width[, fillchar])
1 2 3 4 5 str .startswith(sub[,start[,end]])str .endswith(sub[,start[,end]])
strip():删除串前后(左右两侧)的空格或特殊字符
1 2 3 4 5 6 7 8 9 10 11 str = " c.biancheng.net \t\n\r" str .strip()str .strip(" ,\r" )str
lstrip():删除字符串前面(左边)的空格或特殊字符
rstrip():删除字符串后面(右边)的空格或特殊字符
学习 format() 方法的难点,在于搞清楚 str 显示样式的书写格式。在创建显示样式模板时,需要使用{}和:来指定占位符,其完整的语法格式为:
1 { [index][ : [ [fill] align] [sign] [
具体参照:format完整
1 2 3 4 str .encode([encoding="utf-8" ][,errors="strict" ])bytes .decode([encoding="utf-8" ][,errors="strict" ])
表 2-2 encode() 参数
参数
含义
str
表示要进行转换的字符串。
encoding = “utf-8”
指定进行编码时采用的字符编码,该选项默认采用 utf-8 编码。例如,如果想使用简体中文,可以设置 gb2312。
errors = “strict”
指定错误处理方式,其可选择值可以是:
转义字符以 \0、\x 开头,以 \x 开头表示后跟十六进制形势的编码值,Python中的转义字符只能使用八进制或十六进制
ASCII编码共收录了128个字符,\0 、\x 后面最多只能跟两位数字,所以八进制形势并不能表示所有的ASCII字符,只有十六进制才能表示所有的ASCII字符
表3-1 转义字符一览表
转义字符
说明
\n
换行符,将光标位置移到下一行开头。
\r
回车符,将光标位置移到本行开头。
\t
水平制表符,也即 Tab 键,一般相当于四个空格。
\a
蜂鸣器响铃。注意不是喇叭发声,现在的计算机很多都不带蜂鸣器了,所以响铃不一定有效。
\b
退格(Backspace),将光标位置移到前一列。
\\
反斜线
\’
单引号
\"
双引号
\
在字符串行尾的续行符,即一行未完,转到下一行继续写。
位运算符是指按照数据在内存中的二进制位进行操作
表3-2 位运算符一览表
位运算符
说明
适用形式
举例
&
按位与
a & b
4 & 5
|
按位或
a | b
4 | 5
^
按位异或
a ^ b
4 ^ 5
~
按位取反
~a
~4
<<
按位左移
a << b
4 << 2,表示整数 4 按位左移 2 位
>>
按位右移
a >> b
4 >> 2,表示整数 4 按位右移 2 位
表3-3 比较运算符一览表
比较运算符
说明
>
大于,如果>前面的值大于后面的值,则返回 True,否则返回 False。
<
小于,如果<前面的值小于后面的值,则返回 True,否则返回 False。
==
等于,如果==两边的值相等,则返回 True,否则返回 False。
>=
大于等于(等价于数学中的 ≥),如果>=前面的值大于或者等于后面的值,则返回 True,否则返回 False。
<=
小于等于(等价于数学中的 ≤),如果<=前面的值小于或者等于后面的值,则返回 True,否则返回 False。
!=
不等于(等价于数学中的 ≠),如果!=两边的值不相等,则返回 True,否则返回 False。
is
判断两个变量所引用的对象是否相同,如果相同则返回 True,否则返回 False。
is not
判断两个变量所引用的对象是否不相同,如果不相同则返回 True,否则返回 False。
== 用来比较两个变量的值是否相等,而 is 则用来比对两个变量引用的是否是同一个对象
1 2 3 4 5 import time t1 = time.gmtime() t2 = time.gmtime() print(t1 == t2) print(t1 is t2)
运行结果:
1 2 3 4 5 True False ''' time 模块的 gmtime() 方法用来获取当前的系统时间,精确到秒级,因为程序运行非常快,所以 t1 和 t1 得到的时间是一样的。== 用来判断 t1 和 t2 的值是否相等,所以返回 True。 '''
表3-4 逻辑运算符一览表
逻辑运算符
含义
基本格式
说明
and
逻辑与运算,等价于数学中的“且”
a and b
当 a 和 b 两个表达式都为真时,a and b 的结果才为真,否则为假。
or
逻辑或运算,等价于数学中的“或”
a or b
当 a 和 b 两个表达式都为假时,a or b 的结果才是假,否则为真。
not
逻辑非运算,等价于数学中的“非”
not a
如果 a 为真,那么 not a 的结果为假;如果 a 为假,那么 not a 的结果为真。相当于对 a 取反。
1 2 3 4 5 6 7 max = a if a>b else bif a>b: max = a; else : max = b;
表 3-5 数字操作符(优先级递减)
操作符
操作
示例
值
**
指数
2**3
8
%
取模/取余数
22%8
6
//
整除/商数取整
22//8
2
/
除法
22/8
2.75
*
乘法
3*5
15
*
字符串复制
[‘s’] * 4
[‘s’, ‘,s’, ‘s’, ‘s’]
-
减法
5-2
3
+
加法
2+2
4
pass 是 Python 中的关键字,用来让解释器跳过此处,什么都不做
1 2 3 4 5 6 7 8 9 10 11 age = int ( input ("请输入你的年龄:" ) ) if age < 12 : print("婴幼儿" ) elif age >= 12 and age < 18 : print("青少年" ) elif age >= 18 and age < 30 : print("成年人" ) elif age >= 30 and age < 50 : pass else : print("老年人" )
assert 语句,又称断言语句,可看做是功能缩小版的 if 语句,用于判断某个表达式的值,如果值为真,则程序可以继续往下执行;反之,会报 AssertionError 错误
1 2 3 4 5 6 7 assert 表达式if 表达式==True : 程序继续执行 else : 程序报 AssertionError 错误
1 2 3 4 5 6 7 8 9 10 11 12 13 14 my_list = [11 ,12 ,13 ] my_tuple = (21 ,22 ,23 ) print([x for x in zip (my_list,my_tuple)]) my_dic = {31 :2 ,32 :4 ,33 :5 } my_set = {41 ,42 ,43 ,44 } print([x for x in zip (my_dic)]) my_pychar = "python" my_shechar = "shell" print([x for x in zip (my_pychar,my_shechar)])
运行结果
1 2 3 [(11 , 21 ), (12 , 22 ), (13 , 23 )] [(31 ,), (32 ,), (33 ,)] [('p' , 's' ), ('y' , 'h' ), ('t' , 'e' ), ('h' , 'l' ), ('o' , 'l' )]
reserved() 可以返回一个给定序列的逆序序列
1 2 3 4 5 6 7 8 9 10 11 print([x for x in reversed ([1 ,2 ,3 ,4 ,5 ])]) print([x for x in reversed ((1 ,2 ,3 ,4 ,5 ))]) print([x for x in reversed ("abcdefg" )]) print([x for x in reversed (range (10 ))])
运行结果
1 2 3 4 [5 , 4 , 3 , 2 , 1 ] [5 , 4 , 3 , 2 , 1 ] ['g' , 'f' , 'e' , 'd' , 'c' , 'b' , 'a' ] [9 , 8 , 7 , 6 , 5 , 4 , 3 , 2 , 1 , 0 ]
sorted() 用于给序列(列表、元组、字典、集合、字符串)进行排序
1 2 3 4 5 list = sorted (iterable, key=None , reverse=False ) ''' key 参数可以自定义排序规则 reverse 参数指定以升序(False,默认)还是降序(True)进行排序 '''
在写 python 程序时,难免会遇到一些需求,比如给别人写一个小工具什么的但是除了写 Python 的,绝大多数人电脑里都没有Python 编译器,所以打包成 exe,让 Windows 用户双击就可以打开,就非常方便了。
打包最常用的工具有 py2exe, cxfree, pyinstaller 等多种方法,不同方法的优缺点自行谷歌,经过多次尝试和对比,笔者觉得 pyintaller 是最方便使用的,因此本节以 pyintaller 为例介绍如何将 py 文件打包为 exe 可执行文件。
安装 pyinstaller
1 2 3 4 pip install pyinstaller pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyinstaller
打包命令
1 2 3 4 5 6 pyinstaller -F -w py-file-path --distpath=outputpath pyinstaller -F -w "./excel_to_word.py" --distpath="./output"
虽然这种方式较为简单,但是打包过程非常缓慢,同时结果文件非常大,笔者写了一个十几行的代码,打包出来的代码有足足 387M。
有人说,这是因为 Anaconda 里内置了很多库,打包的时候打包了很多不必要的模块进去,要用纯净的 Python 来打包。因此介绍如何给 exe 文件瘦身。
最后打包出来的文件足足缩小了十几倍,仅剩十几兆,因此,虽然该方法会麻烦些,但建议使用该方法进行打包。
1 2 3 4 5 6 7 8 9 10 11 12 cd "D:\Program Datas\Python\Venv" python -m venv pyintall cd ".\pyintall\Scripts\" # 激活虚拟环境 activate.abat # 退出当前虚拟环境 .\venv\Scripts\deactivate.bat